The Database Community (e.g., see this symposium on data markets) has recently been championing frameworks for data access, search, commodification, manipulation, extraction, refinement, and storage. I heard about data markets from Eugene Wu; it seems like a market area and research opportunity that is ripe for exploration.
In recent work that was presented in-person by Jerry at VLDB 2023, we wrote about a data search platform (called Saibot) that satisfies differential privacy. Essentially, the main algorithm is able to identify augmentations (join or union compatible via the group operations +, x) that will lead to highly accurate models (the evaluation objective is the 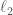
Opportunities and Challenges in Data Markets
- Data Quality and Accuracy: In my opinion, the biggest challenge to the proliferation of data markets is the availability of high-quality data. No amount of analytical sophistication can get over the basic problem of high-quality data. For example, there are certain subgroups in America (e.g., African-American females) that are under-represented in datasets about academia. In fact, most academic departments in the U.S. do not even have any African-Amerian females. So if a social science researcher wishes to study the academic progression of women in academia and observe trends, the researcher cannot make broad claims about departments that do not even have a single Black woman. So first the researcher must seek out data sources of higher quality. e.g., by including data from HBCUs (Historically Black Colleges and Universities).
- Privacy and Security Concerns: Suppose a hospital has data on patient check-ins, health, characteristics, and disorders. If released, the data could help researchers gain valuable insight about diseases in specific areas. Unfortunately, it is known that exactly releasing aggregate information about individuals (even from datasets that are “anonymized”) could lead to de-anonymization/re-identification attacks. Our work on Saibot provides mechanisms to ensure that data search platforms satisfy certain notions of differential privacy.
- Collaboration and Knowledge Sharing: Data markets encourage collaboration between organizations and industries. They facilitate the sharing of knowledge and expertise, breaking down silos (especially within academia) and fostering a culture of collective problem-solving. However, one could ask: how much collaboration—between industries—is needed to solve a problem or achieve a certain level of accuracy for statistical models? This problem needs further study.
- Economic Value: Some technology companies (e.g., Netflix and Facebook) earn their value proposition (almost) entirely from having lots of users and interactions on their platforms. Having more specific forms of data (e.g., the data on African-American females) could give companies a competitive advantage in data markets. So having access to data markets can create new revenue streams. I would personally like to see more economic analysis of the value of data markets!
