tl;dr anyone who previously used or currently uses mathematical tools to solve problems in their field (whether in sciences, pure or applied mathematics, engineering, economics, and so on) needs to pay attention to discussions around the use of AI to solve mathematically precise problems. The revolution has begun!
Here’s what I believe: once AI-assisted proofs become abundant, their scarcity value will fall and attention will shift toward the harder tasks of formulating compelling conjectures, building theories, and creating definitions that organize rapidly expanding bodies of results. The analogy is economic: just as an influx of currency can produce inflation rather than lasting wealth, an influx of proofs can reduce the value attached to any individual proof without necessarily producing a comparable increase in understanding.
Firsthand Experience
Honestly, for me, the question of how useful AI could be in solving math problems did not begin in 2026. In November of 2022, ChatGPT was released. I had just begun my postdoc. With support from the Simons Foundation, I started thinking seriously in 2022 about what mathematics (and intellectual work more broadly) might look like in a world with advanced AI. At the time, much of this remained speculative: What would happen if mathematical reasoning became inexpensive? Which parts of research would retain their value? Would the bottleneck shift from proving statements to identifying the right questions, definitions, and conceptual frameworks?
At ICM (International Congress of Mathematicians) 2026, Terence Tao gave a lecture on Mathematics in the Age of AI. I’d encourage everyone to, at least, read the slides! Tao disusses the implications of the abundance of proofs (not necessarily correct). Recent events have made this transition feel concrete rather than hypothetical. While I was watching the 2026 World Cup final, Levent Alpöge announced a counterexample (credited to the AI system Fable) to the Jacobian conjecture. More precisely, the construction disproves the conjecture in dimension three, and therefore in every dimension 
In recent days have also tested advanced AI systems on several problems from my own active research agenda. These were not merely exercises with known answers: in multiple cases, the systems made progress that appeared genuinely novel, uncovering arguments or directions that I had not previously considered. The important question is no longer whether AI can occasionally imitate mathematical reasoning. It is now clear that AI can perform at least some research-level mathematics. The remaining questions concern the breadth and reliability of that ability, the amount of human guidance and computation it requires, and, most importantly, how the mathematical community should evaluate, explain, verify, and build upon the resulting work.
Terence Tao on Mathematics in the Age of AI
In the rest of this blog post, I will highlight a few parts of his talk which I found illuminating!
Tao identifies the central challenge posed by mathematical AI: not merely generating correct proofs, but transforming those proofs into shared human understanding. That is, the most important question is no longer whether artificial intelligence can prove difficult theorems. I believe that Tao deliberately set that question aside. Instead, he asked what may be a more consequential question:
If AI systems become capable of performing a substantial fraction of research-level mathematical work, what exactly should the mathematical community be trying to accomplish?
We all need to think of that shift (from technological capability to institutional purpose). Most discussions of AI and mathematics focus on benchmark performance: Can a model solve Olympiad problems? Can it formalize a proof in Lean? Can it make progress on an open conjecture? Tao’s lecture asks what happens after the answer to some of those questions becomes yes. Tao asks the audience to provisionally assume that reasonably capable mathematical AI is coming. He then investigates what follows for proof, exposition, reviewing, education, authorship, and the organization of mathematical knowledge.
What I appreciate from the talk is that the resulting picture is neither utopian nor apocalyptic. (Although a large fraction of folks see it as a warning.) Clearly, we are headed towards an era in which proofs are scarce to one in which proofs are abundant; our present institutions are designed almost entirely for the former world, where proofs are not abundant.
A crisis of values rather than a crisis of logic
In the late nineteenth and early twentieth centuries, mathematicians were forced to examine assumptions that had previously remained largely implicit. Russell’s paradox, the emergence of competing foundational programs, and Gödel’s incompleteness theorems created a period of uncertainty about sets, numbers, infinity, axioms, and formal proof. This led to the development of more explicit and standardized foundations that gave mathematicians a trusted environment in which to work.
Tao suggests that AI is producing a comparable period of turbulence, although the foundations now at issue are not primarily logical. They are the foundations of mathematical values and practices: what counts as progress, who deserves credit, what authors are responsible for, why proofs matter, and what the profession is ultimately trying to produce. A disruptive development can expose assumptions that were previously invisible because they rarely came into conflict. Before AI, several goals of mathematics tended to advance together. A mathematician who solved a difficult problem often developed a new technique, trained students, wrote an influential paper, helped organize a research community, and contributed to a larger theory. Because those outputs were correlated, institutions could reward one visible quantity, such as the publication of a paper with one or more important theorems, and assume that the others would follow.
AI threatens to break those correlations.
The two questions that are often confused
Tao separates the AI debate into two questions.
The first is a capability question: Will AI tools, at an acceptable cost and with some level of human supervision, be able to perform meaningful research-level mathematical tasks with a nontrivial rate of success?
Tao formulates this as a family of conjectures because almost every term requires qualification. Which tools? Which fields? What counts as research-level? How much supervision? At what cost? What success rate? What standard of correctness? What standard of exposition? A system that autonomously proves 80 percent of new theorems in algebraic geometry is very different from one that occasionally completes a technical lemma after several days of expert prompting. Both might satisfy some version of an AI capability claim. Tao also stresses that public evidence is affected by reporting bias, commercial incentives, undisclosed compute budgets, selective demonstrations, and ambiguous levels of human assistance. The truth of a capability claim must also be separated from whether that capability is desirable.
The second question is a question about goals and values: What are the mathematical community’s actual objectives, including the implicit objectives encoded in publication, hiring, funding, prizes, and professional prestige? Tao’s key methodological move is to condition on a working hypothesis: suppose that a reasonably strong version of the capability claim becomes true reasonably soon. He does not ask the audience to endorse or welcome the hypothesis. He asks what the community should do if it holds. Very reasonable! This is a useful form of reasoning under uncertainty. To continue to do mathematics, we cannot wait until every capability forecast is resolved before examining whether our institutions are robust to rapid automation. Even a moderate probability of large changes can justify preparing publishing policies, authorship standards, review infrastructure, and educational norms.
First Proof
Tao briefly points to the First Proof project as one of the better-controlled pieces of evidence about current AI capabilities. For its second batch, First Proof assembled ten unpublished research-level problems originating in the work of research mathematicians. Four systems were tested in a controlled environment. The outputs were evaluated using a double-blind journal-review model involving approximately thirty experts, with each submission examined by multiple referees. Across the four systems, seven of the ten problems received at least one solution judged essentially correct or in need of only minor revisions. One system found a novel solution to a stochastic partial differential equations problem that differed from the human proof and impressed the referees. Other problems saw little or no meaningful progress.
The results are substantial, but their limitations are equally informative. The systems often handled routine portions of an argument in meticulous detail while moving too quickly through the genuinely difficult step. Referees found unsupported appeals to supposedly standard arguments, incorrect or missing citations, unnecessary notation, and lengthy explanations of facts that an expert would normally omit. Some submissions reproduced distinctive language and notation from earlier work without appropriate attribution (i.e., behavior that would raise serious plagiarism concerns in a human submission).
The computational costs also varied dramatically. In the reported runs, per-problem costs ranged from single-digit dollar amounts to nearly one thousand dollars, depending on the system and problem. This reinforces Tao’s point that “AI solved the problem” is not a complete scientific statement without information about models, harnesses, prompts, search procedures, human intervention, tokens, time, and cost.
Most importantly, First Proof evaluated only one part of mathematical research: generating proofs of questions selected and formulated by humans. Its organizers explicitly distinguish solving questions within existing frameworks from the equally important work of asking new questions and developing the frameworks in which those questions become meaningful.
Mathematics has more than one objective
What is mathematical research for?
Tao identifies several answers:
- solving pure and applied problems;
- building theories and techniques;
- understanding the natural and social world;
- training future mathematicians (part of my job);
- sustaining a mathematical community;
- contributing to a shared network of knowledge;
- creating works of enduring intellectual or aesthetic value.
Historically, progress along these dimensions was positively correlated. Solving an important problem often required theory building. Theory building produced reusable techniques. Writing and teaching those techniques helped train students and build a community. This made it tempting to treat theorem production as a proxy for mathematical progress. Tao invokes Goodhart’s law: once a proxy becomes an explicit target, optimization can destroy the relationship that made the proxy useful. AI makes this danger especially severe because it can lower the cost of producing objects that look like the outputs rewarded by current metrics.
Suppose an institution rewards:
- the number of problems solved;
- the number of papers published;
- being first to announce a proof;
- benchmark scores;
- citation counts;
- the number of formalized theorems.
An AI-intensive workflow may increase each of these without proportionately increasing understanding, theory, pedagogy, reliability, or long-term usefulness.
A thousand isolated proofs are not necessarily more valuable than one conceptual framework explaining why all thousand theorems are true. A technically correct argument is not necessarily a useful argument. A formally verified statement is not necessarily the statement that mathematicians intended to prove. A highly cited result is not necessarily well understood.
The deeper point is that mathematical knowledge is not a warehouse of theorem statements. It is an organized system of concepts, explanations, analogies, techniques, examples, counterexamples, and judgments about what matters.
Tao’s proposed “oral defense” standard
Tao offers a rule of thumb: a result should not be published unless its human authors can convincingly present a clear, correct, properly attributed expert-level explanation of it. The proposal addresses several problems simultaneously.
An author capable of defending the result is more likely to have:
- checked that the theorem says what it is supposed to say;
- located the crucial step;
- understood the relationship to prior work;
- detected misleading AI-generated exposition;
- assumed meaningful responsibility for correctness.
The idea resembles a thesis defense. Producing a document is not enough; the author must demonstrate command of its content. As a literal universal publication requirement, however, the rule would need careful implementation. It is bound to be controversial: Oral presentation ability varies, and a rigid talk requirement could disadvantage researchers with disabilities, non-native speakers, or authors whose strengths lie in writing rather than performance. Large collaborations may also have genuinely distributed understanding.
The underlying principle is stronger than any particular format: publication should require evidence of human intellectual ownership and accountability. That evidence might take the form of a seminar, an annotated proof map, a technical interview, an expository companion, or an independent human audit. (I’m hoping to implement the oral defense standard within my research group.)
Selected references and further reading
Terence Tao, Mathematics in the Age of AI, ICM public-lecture slides, July 24, 2026. (Teorth)
Mohammed Abouzaid et al., First Proof: Second Batch Report, 2026. (First Proof Project)
William P. Thurston, On Proof and Progress in Mathematics, Bulletin of the American Mathematical Society, 1994. (arXiv)
Tanya Klowden and Terence Tao, Mathematical Methods and Human Thought in the Age of AI, 2026. (arXiv)
Johan Commelin, Mateja Jamnik, Rodrigo Ochigame, Lenny Taelman, and Akshay Venkatesh, Shaping the Future of Mathematics in the Age of AI, 2026. (arXiv)
Jeremy Avigad, Mathematicians in the Age of AI, 2026. (arXiv)
Leiden Declaration on Artificial Intelligence and Mathematics, June 2026. (Leiden AI & Math Declaration)
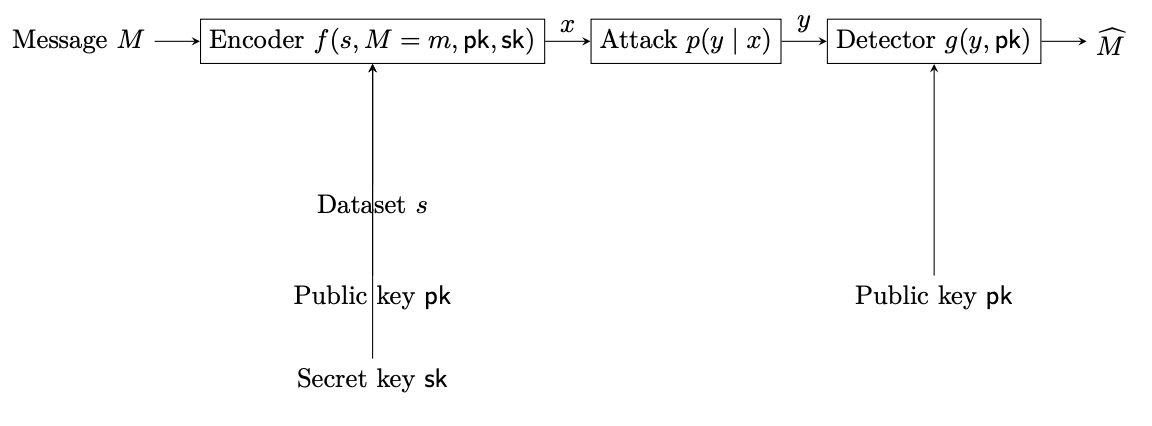
 ) over the vocabulary, and the watermarker chooses a nearby distribution (
) over the vocabulary, and the watermarker chooses a nearby distribution ( ) from which it samples. This turns multi-bit text watermarking into a channel coding problem with a distributional constraint.
) from which it samples. This turns multi-bit text watermarking into a channel coding problem with a distributional constraint. ordinary model versus
ordinary model versus  watermarked model.
watermarked model.
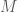 is the hidden message,
is the hidden message,  is the generated text, and
is the generated text, and  is the decoded message. The receiver may know a secret key, a public codebook, and perhaps the base model. The adversary may try to detect, remove, forge, or corrupt the watermark.
is the decoded message. The receiver may know a secret key, a public codebook, and perhaps the base model. The adversary may try to detect, remove, forge, or corrupt the watermark. be the vocabulary. At time
be the vocabulary. At time 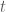 , the base LLM gives
, the base LLM gives

 . The encoder maps
. The encoder maps  into a state
into a state

 should remain close to the base law
should remain close to the base law  . A watermarked distribution is called uniformly per-key
. A watermarked distribution is called uniformly per-key  -distortion-free when, for every time, message, and realized key, the conditional token distribution stays within
-distortion-free when, for every time, message, and realized key, the conditional token distribution stays within 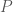 or
or  .
. . Its distinguishing advantage is
. Its distinguishing advantage is ![\Pr_{X\sim P}[\phi(X)=1] - \Pr_{X\sim Q}[\phi(X)=1]](https://s0.wp.com/latex.php?latex=%5CPr_%7BX%5Csim+P%7D%5B%5Cphi%28X%29%3D1%5D+-+%5CPr_%7BX%5Csim+Q%7D%5B%5Cphi%28X%29%3D1%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002) .
.![\mathbb E_P[\phi(X)]-\mathbb E_Q[\phi(X)] = \sum_x \phi(x)(P(x)-Q(x)).](https://s0.wp.com/latex.php?latex=%5Cmathbb+E_P%5B%5Cphi%28X%29%5D-%5Cmathbb+E_Q%5B%5Cphi%28X%29%5D+%3D+%5Csum_x+%5Cphi%28x%29%28P%28x%29-Q%28x%29%29.&bg=ffffff&fg=4c4c4c&s=0&c=20201002)

 ,
, 

 . Taking the absolute value allows either
. Taking the absolute value allows either ![\sup_\phi \left| \Pr_{P}[\phi(X)=1]-\Pr_Q[\phi(X)=1]\right| = d_{\mathrm{TV}}(P,Q).](https://s0.wp.com/latex.php?latex=%5Csup_%5Cphi+%5Cleft%7C+%5CPr_%7BP%7D%5B%5Cphi%28X%29%3D1%5D-%5CPr_Q%5B%5Cphi%28X%29%3D1%5D%5Cright%7C+%3D+d_%7B%5Cmathrm%7BTV%7D%7D%28P%2CQ%29.&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
 -DP if, for all neighboring datasets
-DP if, for all neighboring datasets  and all measurable events
and all measurable events 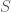 ,
,![Pr[M(D)\in S]\leq e^\varepsilon Pr[M(D')\in S]+\delta.](https://s0.wp.com/latex.php?latex=Pr%5BM%28D%29%5Cin+S%5D%5Cleq+e%5E%5Cvarepsilon+Pr%5BM%28D%27%29%5Cin+S%5D%2B%5Cdelta.&bg=ffffff&fg=4c4c4c&s=0&c=20201002)

 . In our paper, we recall this definition and notes that RDP can be converted back into approximate DP using the standard conversion: if a mechanism satisfies
. In our paper, we recall this definition and notes that RDP can be converted back into approximate DP using the standard conversion: if a mechanism satisfies  -RDP, then it also satisfies
-RDP, then it also satisfies  -DP.
-DP. . The mechanism is trained repeatedly on a dataset
. The mechanism is trained repeatedly on a dataset  without the canary and on the neighboring dataset
without the canary and on the neighboring dataset  with the canary. After training, the auditor measures the loss of the trained model on the canary. This produces two empirical distributions of losses: one from canary-absent training and one from canary-present training. The audit then estimates the Rényi divergence between these two loss distributions. This is a natural black-box attack because if the model behaves differently on the canary depending on whether it was included in training, then the canary has influenced the learned model. In privacy terms, the output distributions
with the canary. After training, the auditor measures the loss of the trained model on the canary. This produces two empirical distributions of losses: one from canary-absent training and one from canary-present training. The audit then estimates the Rényi divergence between these two loss distributions. This is a natural black-box attack because if the model behaves differently on the canary depending on whether it was included in training, then the canary has influenced the learned model. In privacy terms, the output distributions  and
and  are distinguishable.
are distinguishable. .
. is not available. Direct plug-in estimation is usually impossible.
is not available. Direct plug-in estimation is usually impossible.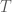 in our work) that try to distinguish samples from
in our work) that try to distinguish samples from  . Second, the expectations in the objective must be approximated using minibatches. Naive minibatch estimates can be unstable because exponential moments are sensitive to outliers. To address this, the paper follows the MINE approach of using minibatching together with an exponential moving average, or EMA. EMA stabilizes the stochastic gradients by smoothing estimates of the exponential terms across minibatches. The paper explicitly notes that this is especially helpful for larger Rényi orders, although variants of this estimator can still have high mean-squared error at larger
. Second, the expectations in the objective must be approximated using minibatches. Naive minibatch estimates can be unstable because exponential moments are sensitive to outliers. To address this, the paper follows the MINE approach of using minibatching together with an exponential moving average, or EMA. EMA stabilizes the stochastic gradients by smoothing estimates of the exponential terms across minibatches. The paper explicitly notes that this is especially helpful for larger Rényi orders, although variants of this estimator can still have high mean-squared error at larger ![\alpha\in(1,2]](https://s0.wp.com/latex.php?latex=%5Calpha%5Cin%281%2C2%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002) , where the estimator is more reliable.
, where the estimator is more reliable.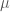 -GDP,
-GDP,  and
and  . For example, at
. For example, at 