Recently, I’ve been investigating computational notions of entropy and had to use the Leftover Hash Lemma. (A variant of this lemma is stated below) I first encountered the Lemma several years ago but didn’t have to use it for anything… until now!
The lemma is attributed to Impagliazzo, Levin, and Luby [1]. A corollary of the lemma is that one can convert a source of (high-enough) Rényi entropy into a distribution that is uniform (or close to uniform). Before stating the Lemma, I’ll discuss a few different notions of entropy, including the classic Shannon Entropy, min-entropy, max-entropy, and so on. See [2] for many different applications for the entropy measures.

Entropy Measures
Consider the random variable 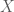


![H_X(x) = \log\frac{1}{\mathbb{P}[X=x]}](https://s0.wp.com/latex.php?latex=H_X%28x%29+%3D+%5Clog%5Cfrac%7B1%7D%7B%5Cmathbb%7BP%7D%5BX%3Dx%5D%7D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)


- Shannon Entropy:
- Min-Entropy:
- Rényi Entropy:
- Max-Entropy:
![H(X) = \mathbb{E}_{x\xleftarrow{R} X}[H_X(x)]](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+%5Cmathbb%7BE%7D_%7Bx%5Cxleftarrow%7BR%7D+X%7D%5BH_X%28x%29%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)



How should we interpret these measures? The min-entropy can be seen as a worst-case measure of how “random” a random variable is. The Rényi entropy measure, intuitively, measures how “collision-resistant” a random variable is (i.e., think hash functions). In my opinion, max-entropy does not give much information, except for how large the support of a random variable is. These entropy measures are related by this inequality:

The inequality above is tight if and only if
A function family 

![\mathbb{P}_{h\xleftarrow{R}\mathcal{H}}[h(x) = h(x')]\leq 1/|\mathcal{R}|](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D_%7Bh%5Cxleftarrow%7BR%7D%5Cmathcal%7BH%7D%7D%5Bh%28x%29+%3D+h%28x%27%29%5D%5Cleq+1%2F%7C%5Cmathcal%7BR%7D%7C&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
The Lemma
Statement: Let 






One can interpret the statement above as saying that you can convert a random variable with high-enough Rényi entropy into a random variable that is very close to uniform.
References
[1] Impagliazzo, Russell; Levin, Leonid A.; Luby, Michael (1989). Pseudo-random Generation from one-way functions.
[2] Iftach Haitner and Salil Vadhan. The Many Entropies in One-Way Functions, pages 159–217. Springer International Publishing, 2017
