At SIGMOD 2025, my collaborators and I are scheduled to give a tutorial on Privacy and Security in Distributed Data Markets. The core material that will be presented is summarized in the accompanying paper.
Abstract
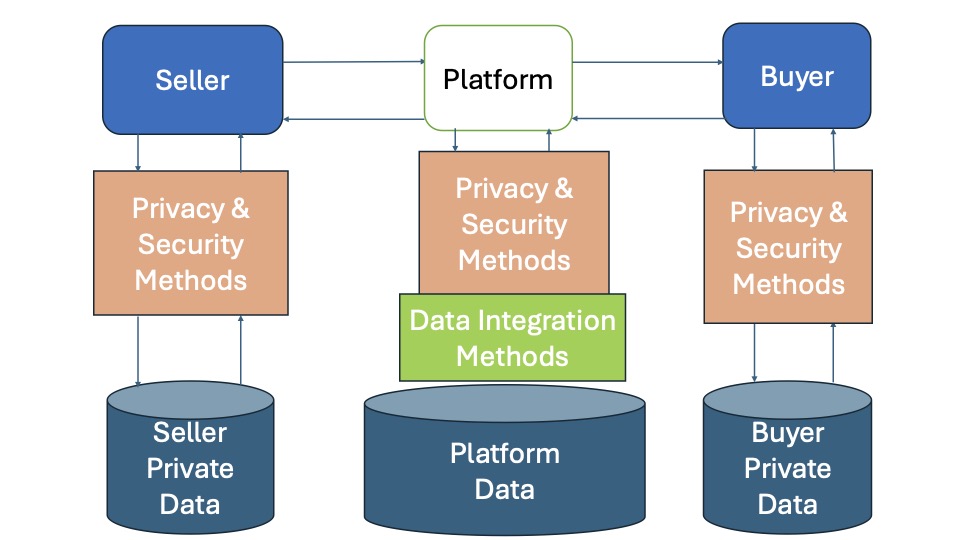
Data markets play a pivotal role in modern industries by facilitating the exchange of data for predictive modeling, targeted marketing, and research. However, as data becomes a valuable commodity, privacy and security concerns have grown, particularly regarding the personal information of individuals. This tutorial explores privacy and security issues when integrating different data sources in data market platforms. As motivation for the importance of enforcing privacy requirements, we discuss attacks on data markets focusing on membership inference and reconstruction attacks. We also discuss security vulnerabilities in decentralized data marketplaces, including adversarial manipulations by buyers or sellers. We provide an overview of privacy and security mechanisms designed to mitigate these risks. In order to enforce the least amount of trust for buyers and sellers, we focus on distributed protocols. Finally, we conclude with opportunities for future research on understanding and mitigating privacy and security concerns in distributed data markets.
Schedule
Part I: Survey on Data Markets
Part II: Privacy and Security Risks
Part III: Privacy-Preserving Technologies and Security Tools
Part IV: Regulatory Considerations
Part V: Open Problems & Future Work
Part VI: Q & A
Leading up to the conference, I’m planning to post on different aspects of the tutorial.
