Every year, I get annual reports for some organizations that I’m affiliated with (e.g., the Simons Foundation). The Annual Report summarizes what the organization accomplished through grant-making, in-house research, outreach activities, and so on. The report is both reflective and forward-looking. In the final blog post of this year, I will write a brief annual report for myself.
Harvard Commencement 2023
Technically, I earned my Ph.D. in 2022: I defended and submitted my dissertation in the 2022 calendar year. But I did not attend the 2022 commencement ceremony as I knew it would take significant effort to have a subset of my extended family attend the ceremony. In 2023, the Alabi family showed up and it was a glorious way to officially culminate my graduate career. Sometimes, I think the general public underestimates how much support from friends/family is necessary to succeed in academia (especially, during the latter years of the Ph.D. when the dissertation writing process is more likely to be more isolating than earlier years). I am blessed to have a strong support network of friends and family.

NaijaCoder
The NaijaCoder 2023 summer camp took place in Abuja, Nigeria. Alida Monaco and I were the main instructors for the class of 2023. The camp ran for 2 weeks. Every day, we had 6-hour lectures with a lunch break. Despite the intense schedule, the students were really engaged in class 🔥🧠.
The 2023 camp was physically located in the premises of Lifegate Academy in Abuja. Mr. Anywanwu Ebere is the head of schools; he was pivotal in getting the board of the academy to approve our use of their premises for our activities. We had guest lectures, from EducationUSA (from the U.S. Embassy in Nigeria) and GIEVA (Global Integrated Education Volunteers Education), during which they discussed study-abroad opportunities mostly targeted to U.S. schools. We also wrote up some results of our research on early algorithms education in Nigeria. Check it out: https://arxiv.org/abs/2310.20488 (to appear at SIGCSE 2024).
Planning is underway for the 2024 iteration. Owing to increased demand, we will host the program in Abuja and Lagos. Hopefully, more students from the southern parts of Nigeria can attend the program. There will be more instructors, more participants, and more food. Going forward, we would like to maintain the same rigor as we scale instruction to more participants.
Simons Foundation Junior Fellowship
I am in the middle of my 2nd year as a Junior Fellow in the Simons Society of Fellows. Fellows are expected to attend the weekly dinners. When I’m in town, I go to the dinners. It is always fun to hang out with fellow Junior Fellows and gain wisdom from the Senior Fellows. In March 2023, the Simons Society of Fellows held a retreat at the Ritz Carlton in Sarasota, Florida. For me, the highlight of the trip was going birdwatching!
The Simons Junior Fellowship is a grant, in the applicant’s name, given to an institution in NYC. As such, I am hosted at Columbia University as a post-doc. This year, most of the papers I published centered around data privacy and graph generation algorithms. I have also begun exploring some topics in quantum information. It is nice to have a post-doc that affords me the opportunity to explore interests outside my dissertation topic.
This year, I also spent some time learning from scientists at the Flatiron Institute at the Simons Foundation. I have one ongoing project, with a friend at Flatiron, which I hope to continue in 2024.
2024
Next year, I will continue, at the same pace, with research and my non-profit work. Also, I plan to read more books that are not directly related to my research (e.g., just started reading “Surely You’re Joking, Mr. Feynman!”). Finally, I’m looking forward to the 2024 Simons Society of Fellows retreat in San Juan, Puerto Rico.
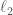 metric but it scales to other objectives as well). This has implications for improving data quality (e..g, perhaps one can identify the right augmentations that will lead to better outcomes) and heterogenous collaboration of all kinds. We evaluate our algorithms on over 300 datasets and compare to leading alternative mechanisms.
metric but it scales to other objectives as well). This has implications for improving data quality (e..g, perhaps one can identify the right augmentations that will lead to better outcomes) and heterogenous collaboration of all kinds. We evaluate our algorithms on over 300 datasets and compare to leading alternative mechanisms.