I attended my first research conference in 2016 in San Francisco, California. In general, I had a nice time and made new connections with fellow students and more established researchers. Then, I had not begun my PhD studies and was not sure what direction my research would take me to! Now, I’ve come full circle and hope to more regularly attend database conferences like PODS/SIGMOD. Recently, I traveled to Santiago, Chile for PODS/SIGMOD.
My blog post can’t do justice to summarizing all the amazing talks/sessions that I attended. Check out the conference website that details the PODS/SIGMOD keynotes and special events.
Recently, I’ve been investigating computational notions of entropy and had to use the Leftover Hash Lemma. (A variant of this lemma is stated below) I first encountered the Lemma several years ago but didn’t have to use it for anything… until now!
The lemma is attributed to Impagliazzo, Levin, and Luby [1]. A corollary of the lemma is that one can convert a source of (high-enough) Rényi entropy into a distribution that is uniform (or close to uniform). Before stating the Lemma, I’ll discuss a few different notions of entropy, including the classic Shannon Entropy, min-entropy, max-entropy, and so on. See [2] for many different applications for the entropy measures.
Entropy Measures
Consider the random variable . We use to denote that the element is randomly drawn from . Denote its support by Supp(). Define the sample entropy of with respect to as . The sample entropy measures how much randomness is present in the sample when generated according to the law/density-function of . Also, let when Supp(). Then we can state the entropy measures in terms of the sample entropy:
Shannon Entropy:
Min-Entropy:
Rényi Entropy:
Max-Entropy:
How should we interpret these measures? The min-entropy can be seen as a worst-case measure of how “random” a random variable is. The Rényi entropy measure, intuitively, measures how “collision-resistant” a random variable is (i.e., think hash functions). In my opinion, max-entropy does not give much information, except for how large the support of a random variable is. These entropy measures are related by this inequality:
The inequality above is tight if and only if is uniformly distributed on its support. The statement of the lemma below uses universal hash functions. Here is a definition:
A function family is two-universal if , the following holds: .
The Lemma
Statement: Let be a random variable over with . Consider the two-universal function family . Then for any , the statistical distance between and is at most .
One can interpret the statement above as saying that you can convert a random variable with high-enough Rényi entropy into a random variable that is very close to uniform.
References
[1] Impagliazzo, Russell; Levin, Leonid A.; Luby, Michael (1989). Pseudo-random Generation from one-way functions.
[2] Iftach Haitner and Salil Vadhan. The Many Entropies in One-Way Functions, pages 159–217. Springer International Publishing, 2017
Following an amazing experience at the retreat in 2023, the Simons Foundation Society of Fellows 2024 retreat was held in San Juan, Puerto Rico during the spring semester break. The major goal of the retreat is to foster intellectual exchange and collaboration amongst the Junior and Senior fellows. We were treated to daily presentations from Senior and Junior Fellows and I learned a lot from the lectures. However, the informal gatherings—on the beach or in the pool—are probably why we enjoy the retreats.
The retreat was physically located in the Fairmont El San Juan hotel in Puerto Rico. The hotel is on the beach and has a night club! There is also a casino where I lost ~$50. (At some point, I was up by almost ~$200.) Better luck next time!
El Yunque National Forest
Objectives and Format
The primary goal of the retreat is to facilitate discussions and interactions that cross traditional academic boundaries, reflecting the foundation’s overarching mission to advance research in basic sciences and mathematics. The event features a series of 20-minute talks delivered by selected Fellows, showcasing a diverse range of research topics from theoretical physics to computational neuroscience.
Highlights from the 2024 Retreat
The 2024 retreat included presentations on various scientific and mathematical topics. I took notes during a subset of the presentations.
For instance, Michael Chapman discussed mathematical approximations and their limits in convergence, while Sanchit Chaturvedi reviewed the historical and mathematical evolution of the theory of gases. Emanuele Galiffi presented on the possibilities of manipulating light through temporal changes in matter, aiming to overcome traditional limitations in optical sciences. Jane Hubbard’s talk focused on how dietary choices and aging affect stem cells, using C. elegans as a model to understand cellular and molecular mechanisms. Isabel Low from Columbia University provided insights into the neural mechanisms that transform memories into actions in birds, a critical survival trait. Additionally, Carol Mason discussed the development of binocular vision and its molecular underpinnings and also discussed questions about the impact of melanin presence in retinal cells. Francesca Mignacco discussed the application of statistical physics to understand large populations of neurons, highlighting the challenges and advancements in interpreting complex neural data. Oliver Philcox’s presentation pondered the asymmetry of the universe, reflecting on how our perceptions are shaped by physical laws. And Andre Toussaint discussed some behavioral and neural signatures of chronic pain and abuse.
I am looking forward to the 2025 retreat! Will it be held in Hawaii?







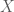 . We use
. We use  to denote that the element
to denote that the element  is randomly drawn from
is randomly drawn from ![H_X(x) = \log\frac{1}{\mathbb{P}[X=x]}](https://s0.wp.com/latex.php?latex=H_X%28x%29+%3D+%5Clog%5Cfrac%7B1%7D%7B%5Cmathbb%7BP%7D%5BX%3Dx%5D%7D&bg=ffffff&fg=4c4c4c&s=0&c=20201002) . The sample entropy measures how much randomness is present in the sample
. The sample entropy measures how much randomness is present in the sample  when
when  Supp(
Supp(![H(X) = \mathbb{E}_{x\xleftarrow{R} X}[H_X(x)]](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+%5Cmathbb%7BE%7D_%7Bx%5Cxleftarrow%7BR%7D+X%7D%5BH_X%28x%29%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)




 is two-universal if
is two-universal if  , the following holds:
, the following holds: ![\mathbb{P}_{h\xleftarrow{R}\mathcal{H}}[h(x) = h(x')]\leq 1/|\mathcal{R}|](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D_%7Bh%5Cxleftarrow%7BR%7D%5Cmathcal%7BH%7D%7D%5Bh%28x%29+%3D+h%28x%27%29%5D%5Cleq+1%2F%7C%5Cmathcal%7BR%7D%7C&bg=ffffff&fg=4c4c4c&s=0&c=20201002) .
. with
with  . Consider the two-universal function family
. Consider the two-universal function family  . Then for any
. Then for any  , the statistical distance between
, the statistical distance between  and
and  is at most
is at most  .
.
