tl;dr 👉 We just put out work on attacking influence-based estimators in data markets. The student lead (who did most of the work) is Tue Do! Check it out. Accurate models are not enough. If the auditing tools we rely on can be fooled, then the trustworthiness of machine learning is on shaky ground.
Modern machine learning models are no longer evaluated solely by their training or test accuracy. Increasingly, we ask:
- Which training examples influenced a particular prediction?
- How much does the model rely on each data point?
- Which data are most valuable, or most dangerous, to keep?
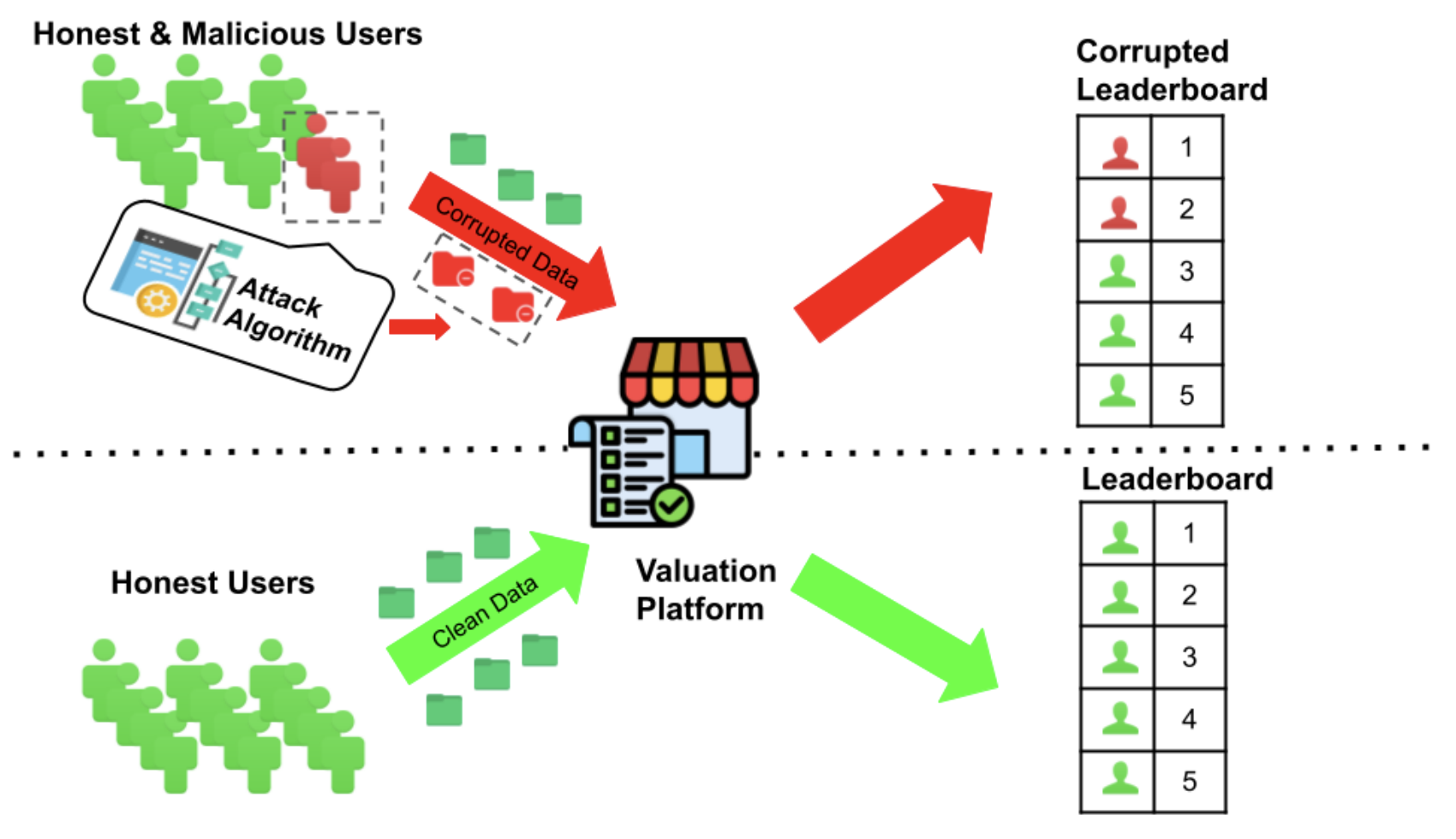
Answering these questions requires influence measures, which are mathematical tools that assign each training example a score reflecting its importance or memorization within the model. These scores are already woven into practice: they guide data valuation (identifying key examples), dataset curation (removing mislabeled or harmful points), privacy auditing (tracking sensitive examples), and even data markets (pricing user contributions).
But here lies the problem: what if these influence measures themselves can be attacked? In our new paper, Efficiently Attacking Memorization Scores, we show that they can. Worse, the attacks are not only possible but efficient, targeted, and subtle.
Memorization Scores: A Primer
A memorization score quantifies the extent to which a training example is “remembered” by a model. Intuitively:
- A point has a high memorization score if the model depends heavily on it (e.g., removing it would harm performance on similar examples).
- A low score indicates the model has little reliance on the point.
Formally, scores are often estimated through:
- Leave-one-out retraining (how accuracy changes when a point is removed).
- Influence functions (approximating parameter sensitivity).
- Gradient similarity measures (alignment between gradients of a point and test loss).
Because they are computationally heavy, practical implementations rely on approximations, which (one could argue) introduces new fragilities.
The Adversarial Setting
We consider an adversary whose goal is to perturb training data so as to shift memorization scores in their favor. Examples include:
- Data market gaming (prime motivation): A seller inflates the memorization score of their data to earn higher compensation.
- Audit evasion: A harmful or mislabeled point is disguised by lowering its score.
- Curation disruption: An attacker perturbs examples so that automated cleaning pipelines misidentify them as low-influence.
Constraints:
The attack could satisfy a few key conditions but we focus on
- Efficiency: The method must scale to modern, large-scale datasets.
- Plausibility: Model accuracy should remain intact, so the manipulation is not caught by standard validation checks.
The Pseudoinverse Attack
Our core contribution is a general, efficient method called the Pseudoinverse Attack: (1) Memorization scores, though nonlinear in general, can be locally approximated as a linear function of input perturbations. This mirrors how influence functions linearize parameter changes. (2) We solve an inverse problem (specified in paper), compute approximate gradients that link input perturbations to score changes, use the pseudo-inverse to find efficient perturbations and apply them selectively to target points. This avoids full retraining for each perturbation and yields perturbations that are both targeted and efficient.
Validation
We validate across image classification tasks (e.g., CIFAR benchmarks) with standard architectures (CNNs, ResNets).
Key Findings
- High success rate: Target scores can be reliably increased or decreased.
- Stable accuracy: Overall classification performance remains essentially unchanged.
- Scalability: The attack works even when applied to multiple examples at once.
Example (Score Inflation): A low-memorization image (e.g., a benign CIFAR airplane) is perturbed. After retraining, its memorization score jumps into the top decile, without degrading accuracy on other examples. This demonstrates a direct subversion of data valuation pipelines.
Why This Is Dangerous
The consequences ripple outward:
- Data markets: Compensation schemes based on memorization become easily exploitable.
- Dataset curation: Automated cleaning fails if adversaries suppress scores of mislabeled or harmful points.
- Auditing & responsibility: Legal or ethical frameworks built on data attribution collapse under adversarial pressure.
- Fairness & privacy: Influence-based fairness assessments are no longer trustworthy.
If influence estimators can be manipulated, the entire valuation-based ecosystem is at risk.
Conclusion
This work sits at the intersection of adversarial ML and interpretability:
- First wave: Adversarial examples. i.e., perturb inputs to fool predictions.
- Second wave: Data poisoning and backdoor attacks. i.e., perturb training sets to corrupt models.
- Third wave (our focus): Attacks on the auditing layer: perturb training sets to corrupt pricing/interpretability signals without harming predictions/accuracy.
This third wave is subtle but potentially more damaging: if we cannot trust influence measures, then even “good” models become opaque and unaccountable. As machine learning moves toward explainability and responsible deployment, securing the interpretability layer is just as critical as securing models themselves.
Our paper reveals a new adversarial frontier: efficiently manipulating memorization scores.
- We introduce the Pseudoinverse Attack, an efficient, targeted method for perturbing training points to distort influence measures.
- We show, supported by theory and experiments, that memorization scores are highly vulnerable, even under small, imperceptible perturbations.
- We argue that this undermines trust in data valuation, fairness, auditing, and accountability pipelines.
