How would you prove you’ve solved a Sudoku puzzle without revealing the solution? You can construct a zero-knowledge proof showing the grid satisfies Sudoku rules (unique numbers per row, column, and box).
This semester, one of my projects involves zero-knowledge proofs. I’ll try to explain what I’ve learned about this amazing concept and its variants (with particular attention to statistical zero-knowledge). Shout out to Boaz’s cryptography class. Zero-knowledge proofs have found profound use in blockchain technology, authentication, privacy, and so on.
Definition
Intuition: Imagine someone wants to prove they know the solution to a complex problem (e.g., a puzzle or how Trump was going to win the election) without revealing the solution. They use a process that convinces the verifier they have the solution without showing it.
A zero-knowledge proof (ZKP) is a method by which one party (the prover) can demonstrate to another party (the verifier) that a specific statement is true without revealing any additional information about the statement itself.
Key Properties of Zero-Knowledge Proofs
There are a few variants of zero-knowledge. Here is one:
- Completeness:
If the statement is true, a honest prover can convince the verifier of its truth:- If
and the prover
knows a valid witness
, then for all
, the honest verifier
will accept the proof with probability at least
:
- If
- Soundness:
If the statement is false, no dishonest prover can convince the verifier that it is true (except with an extremely small probability).- If
, then no cheating prover
can convince the honest verifier
where
is a negligible function.,
- If
- Zero-Knowledge:
The verifier learns nothing other than the fact that the statement is true. No information about how or why the statement is true is revealed.- For every polynomial-time verifier
, there exists a polynomial-time simulator
such that the output of
is computationally indistinguishable from the interaction between
:
- For every polynomial-time verifier
![\Pr[V(x) = \text{accept} \mid x \in L, w \text{ valid}] \geq 1 - \epsilon.](https://s0.wp.com/latex.php?latex=%5CPr%5BV%28x%29+%3D+%5Ctext%7Baccept%7D+%5Cmid+x+%5Cin+L%2C+w+%5Ctext%7B+valid%7D%5D+%5Cgeq+1+-+%5Cepsilon.&bg=ffffff&fg=4c4c4c&s=0&c=20201002)

| Type | Definition | Guarantee |
|---|---|---|
| Perfect Zero-Knowledge | Real and simulated distributions are identical. | Holds even against computationally unbounded verifiers. |
| Statistical Zero-Knowledge | Real and simulated distributions are statistically close (negligible difference). | Holds against computationally unbounded verifiers. |
| Computational Zero-Knowledge | Real and simulated distributions are computationally indistinguishable for polynomial-time verifiers. | Holds only against computationally bounded verifiers. |
Interactive Zero-Knowledge Proofs
These involve a back-and-forth interaction between the prover and the verifier.
- Graph Isomorphism:
Prove that two graphs are isomorphic (structurally identical) without revealing the isomorphism itself. Alice proves to Bob that she knows a way to relabel the nodes of graphto match graph
.
- Hamiltonian Cycle Problem:
Prove that a graph contains a Hamiltonian cycle (a path visiting every vertex exactly once) without revealing the actual cycle.
Non-Interactive Zero-Knowledge Proofs (NIZKs)
These eliminate the need for interaction, enabling the prover to generate a single proof that can be verified multiple times.
- zk-SNARKs (Succinct Non-Interactive Arguments of Knowledge):
Widely used in blockchain systems like Zcash to validate transactions while keeping them private. Example: Prove that a transaction is valid (inputs equal outputs) without disclosing amounts or participants. - zk-STARKs (Scalable Transparent Arguments of Knowledge):
A transparent alternative to zk-SNARKs that avoids the need for trusted setups and is more scalable. Example: Used in Ethereum Layer-2 solutions like StarkNet to bundle transaction proofs.
The Fiat-Shamir Heuristic technique to convert interactive proofs into non-interactive ones using cryptographic hash functions.
- Schnorr Protocol:
A proof that you know a discrete logarithm of a number without revealing the logarithm itself. Example: Prove ownership of a private key without exposing it (used in Schnorr signatures).
Example Use Cases
Zero-knowledge proofs (ZKPs) come in different forms, with specific examples being applied across theoretical and practical scenarios. Below are some notable examples:
1. Commit-and-Prove Protocols
Combine commitments (binding and hiding data) with zero-knowledge proofs (for example Pedersen Commitments). Prove that you committed to a number
2. Bulletproofs
Efficient range proofs that demonstrate a value lies within a specific range without revealing the value. Example: Used in Monero to ensure transaction amounts are positive without disclosing the actual amounts.
3. Proofs in Cloud Computing
- Proof of Retrievability:
Prove a cloud provider stores your data without downloading it. Example: Used in decentralized storage systems like Filecoin. - Proof of Computation:
Demonstrate the correctness of outsourced computation without revealing inputs or outputs.
4. Secure Voting Protocols
- Homomorphic Encryption-Based Proofs:
Prove a vote is valid (e.g., within a candidate set) without revealing the voter’s choice.
5. Knowledge of a Password
- Example: Authenticate to a server by proving knowledge of a password without transmitting it. SRP Protocol (Secure Remote Password): Verifies a user knows a password without sending the password itself.
Perfect Zero-Knowledge
Perfect Zero-Knowledge is a stronger version of zero-knowledge where the verifier cannot distinguish between the interaction with the actual prover and the simulated interaction, even with unlimited computational power. In other words, the simulator’s output is statistically identical to the real interaction transcript, not just computationally indistinguishable.
Formal Definition
Let 


![\Pr[\text{Transcript}(P\leftrightarrow V^*,x)=t]= \Pr[S(x)=t]\forall t,](https://s0.wp.com/latex.php?latex=%5CPr%5B%5Ctext%7BTranscript%7D%28P%5Cleftrightarrow+V%5E%2A%2Cx%29%3Dt%5D%3D+%5CPr%5BS%28x%29%3Dt%5D%5Cforall+t%2C&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
where:
is the transcript of the interaction between
This implies that the probability distributions of the transcripts from the real interaction and the simulated interaction are exactly the same.
Key Features of Perfect Zero-Knowledge
- Statistical Indistinguishability:
The output of the simulator is statistically indistinguishable from the real transcript, meaning the difference between the two distributions is exactly zero. - Stronger Privacy Guarantees:
Since the guarantee holds even against verifiers with infinite computational power, it is stronger than computational zero-knowledge, where the indistinguishability only holds for polynomial-time adversaries.
Example of Perfect Zero-Knowledge
The classic Graph Isomorphism Zero-Knowledge Protocol is a perfect zero-knowledge protocol:
- A prover shows two graphs are isomorphic without revealing the actual isomorphism.
- The verifier cannot distinguish between a genuine interaction and a simulated one, even with infinite computational power, making it perfect zero-knowledge.
Computational Zero-Knowledge
Computational Zero-Knowledge is a type of zero-knowledge proof where the verifier cannot distinguish between the actual interaction with the prover and the output of a simulator, provided the verifier has limited (polynomial-time) computational power.
This means that the zero-knowledge property relies on the computational infeasibility of distinguishing between the two scenarios, often based on cryptographic hardness assumptions (e.g., the difficulty of factoring large numbers or solving discrete logarithms).
Formal Definition
Let 


Key Features of Computational Zero-Knowledge
- Computational Indistinguishability:
The zero-knowledge property holds against adversaries with limited computational power (polynomial-time distinguishers). If the verifier were computationally unbounded, they might be able to differentiate the two distributions. - Cryptographic Assumptions:
Computational zero-knowledge often relies on assumptions like:- The infeasibility of factoring large integers.
- The hardness of the discrete logarithm problem.
- Other complexity-theoretic assumptions.
- Relaxed Privacy Guarantees:
Unlike perfect zero-knowledge, where the simulated and real distributions are statistically identical, computational zero-knowledge only guarantees privacy against computationally bounded adversaries.
Examples of Computational Zero-Knowledge
- zk-SNARKs:
Used in blockchain protocols like Zcash to ensure transaction validity without revealing sensitive details. The zero-knowledge property here relies on computational assumptions. - Interactive Proofs with Commitment Schemes:
Many zero-knowledge protocols use cryptographic commitments (e.g., Pedersen commitments) to hide information during the proof, ensuring the verifier cannot extract more data computationally.
Real-World Importance
Computational zero-knowledge is widely used in practical applications, such as:
- Cryptocurrencies (e.g., Zcash, zkRollups).
- Authentication protocols.
- Privacy-preserving identity verification.
It strikes a balance between strong privacy guarantees and computational efficiency, making it suitable for real-world cryptographic systems.
Statistical Zero-Knowledge
Statistical Zero-Knowledge (SZK) is a type of zero-knowledge proof where the verifier cannot distinguish between the real interaction with the prover and the output of a simulator, even with unlimited computational power. The key difference from perfect zero-knowledge is that the two distributions (real and simulated) are not identical but are statistically close, meaning the difference between them is negligible.
Formal Definition
Let
![\Delta(\text{Transcript}(P \leftrightarrow V^*, x), S(x)) = \frac{1}{2} \sum_t \left| \Pr[\text{Transcript} = t] - \Pr[S(x) = t] \right| \leq \epsilon,](https://s0.wp.com/latex.php?latex=%5CDelta%28%5Ctext%7BTranscript%7D%28P+%5Cleftrightarrow+V%5E%2A%2C+x%29%2C+S%28x%29%29+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Csum_t+%5Cleft%7C+%5CPr%5B%5Ctext%7BTranscript%7D+%3D+t%5D+-+%5CPr%5BS%28x%29+%3D+t%5D+%5Cright%7C+%5Cleq+%5Cepsilon%2C&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
where
Key Features of Statistical Zero-Knowledge
- Statistical Indistinguishability:
The difference between the real and simulated transcripts is negligibly small, even for verifiers with unlimited computational power. - Weaker than Perfect Zero-Knowledge:
Perfect zero-knowledge requires the distributions to be exactly identical, while statistical zero-knowledge allows for a negligible difference. - Stronger than Computational Zero-Knowledge:
Computational zero-knowledge only guarantees indistinguishability for polynomial-time adversaries, whereas statistical zero-knowledge holds against adversaries with unlimited computational power. - No Dependence on Cryptographic Assumptions:
SZK is typically not reliant on computational hardness assumptions, unlike computational zero-knowledge.
Examples of Statistical Zero-Knowledge
- Quadratic Residuosity Problem:
Prove that a number(a composite number) without revealing the factorization of
- Graph Isomorphism Problem:
Prove that two graphsand
are isomorphic without revealing the isomorphism. The verifier’s view of the interaction can be statistically simulated.
Real-World Applications
While SZK is less common in practical applications compared to computational zero-knowledge, it has theoretical importance in cryptographic protocol design and scenarios where absolute guarantees against powerful adversaries are required.
Some References
[1] Goldreich, Oded (2001). Foundations of Cryptography Volume I. Cambridge University Press.
[2] Murtagh, Jack. https://www.scientificamerican.com/article/wheres-waldo-how-to-prove-you-found-him-without-revealing-where-he-is/
[3] Goldwasser, S.; Micali, S.; Rackoff, C. (1989), “The knowledge complexity of interactive proof systems” (PDF), SIAM Journal on Computing, 18 (1): 186–208, doi:10.1137/0218012, ISSN 1095-7111

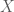 . We use
. We use  to denote that the element
to denote that the element ![H_X(x) = \log\frac{1}{\mathbb{P}[X=x]}](https://s0.wp.com/latex.php?latex=H_X%28x%29+%3D+%5Clog%5Cfrac%7B1%7D%7B%5Cmathbb%7BP%7D%5BX%3Dx%5D%7D&bg=ffffff&fg=4c4c4c&s=0&c=20201002) . The sample entropy measures how much randomness is present in the sample
. The sample entropy measures how much randomness is present in the sample  when
when  Supp(
Supp(![H(X) = \mathbb{E}_{x\xleftarrow{R} X}[H_X(x)]](https://s0.wp.com/latex.php?latex=H%28X%29+%3D+%5Cmathbb%7BE%7D_%7Bx%5Cxleftarrow%7BR%7D+X%7D%5BH_X%28x%29%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)




 is two-universal if
is two-universal if  , the following holds:
, the following holds: ![\mathbb{P}_{h\xleftarrow{R}\mathcal{H}}[h(x) = h(x')]\leq 1/|\mathcal{R}|](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BP%7D_%7Bh%5Cxleftarrow%7BR%7D%5Cmathcal%7BH%7D%7D%5Bh%28x%29+%3D+h%28x%27%29%5D%5Cleq+1%2F%7C%5Cmathcal%7BR%7D%7C&bg=ffffff&fg=4c4c4c&s=0&c=20201002) .
. with
with  . Consider the two-universal function family
. Consider the two-universal function family  . Then for any
. Then for any  , the statistical distance between
, the statistical distance between  and
and  is at most
is at most  .
.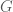 be a graph with vertex degree denoted by
be a graph with vertex degree denoted by  for vertex
for vertex  . Consider the following matrix
. Consider the following matrix 
 is then defined by
is then defined by 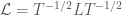 , where
, where 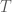 is the diagonal matrix with
is the diagonal matrix with  -th entry having value
-th entry having value 
 on
on 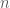 vertices has eigenvalues 0, 1 (with multiplicity
vertices has eigenvalues 0, 1 (with multiplicity  ), and 2.
), and 2. on
on  and
and 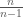 with multiplicity
with multiplicity  .
. on
on 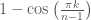 for
for 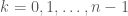 .
. with equality holding if and only if
with equality holding if and only if  . If
. If 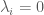 and
and  , then
, then  connected components.
connected components.