
I just finished reading The Usefulness of Useless Knowledge again, this time with the perspective of living through a period of rapid technological acceleration driven by AI. On an earlier reading, Flexner’s defense of curiosity-driven inquiry felt aspirational and almost moral in tone, a principled argument for intellectual freedom. On rereading, it feels more diagnostic. Many of the tensions he identified (i.e., between short-term utility and long-term understanding, between institutional incentives and genuine discovery) now play out daily in how we fund, evaluate, and deploy AI research. What has changed is not the structure of his argument, but its urgency: in a world increasingly optimized for immediate outputs, Flexner’s insistence that transformative advances often arise from questions with no obvious application reads less like an idealistic manifesto and more like a practical warning.
In 1939, on the eve of a world war, Abraham Flexner published a slim, stubbornly optimistic essay with a mischievous title: The Usefulness of Useless Knowledge. His claim is not that practical work is bad. It’s that the deep engine of civilization is often curiosity that doesn’t start with an application in mind, and that trying to force every idea to justify itself immediately is a reliable way to stop the next revolution before it begins.
Robbert Dijkgraaf’s companion essay (and related pieces written from his vantage point at the Institute for Advanced Study) updates Flexner’s argument for a world that is now built out of microelectronics, networks, and software; this is exactly the substrate on which modern AI sits. Reading them together today feels like watching two people describe the same phenomenon across two eras: breakthroughs are usually the delayed interest on “useless” questions.
Below is a guided tour of their core ideas, with a detour through the current AI moment, where “useless” knowledge is quietly doing most of the work.
Flexner’s central paradox: curiosity first, usefulness later
Flexner’s essay is a defense of a particular kind of intellectual freedom: the right to pursue questions without writing an ROI memo first.
Dijkgraaf highlights one of Flexner’s most quoted lines (and the one that best captures the whole stance): “Curiosity… is probably the outstanding characteristic of modern thinking… and it must be absolutely unhampered.”
That “must” is doing a lot of work. Flexner isn’t saying that applications are optional. He’s saying the route to them is often non-linear and hard to predict. He even makes the institutional point: a research institute shouldn’t justify itself by promising inventions on a timeline. Instead: “We make ourselves no promises… [but] cherish the hope that the unobstructed pursuit of useless knowledge” will matter later.
Notice the subtlety: he hopes it will matter, but he refuses to make that the official rationale. Why? Because if you only fund what looks useful today, you’ll underproduce the ideas that define tomorrow.
The “Mississippi” model of discovery (and why it matters for AI)
Flexner is unusually modern in how he describes the innovation pipeline: not as single geniuses striking gold, but as a long chain of partial insights that only later “click.”
He writes: “Almost every discovery has a long and precarious history… Science… begins in a tiny rivulet… [and] is formed from countless sources.”
This is basically an antidote to the myth that research can be managed like a factory. You can optimize a pipeline once you know what the pipeline is. But when you’re still discovering what questions are even coherent, “efficiency” often means “premature narrowing.”
AI is a perfect example of the Mississippi model. Modern machine learning is not one idea; it’s a confluence:
- mathematical statistics + linear algebra,
- optimization + numerical computing,
- information theory + coding,
- neuroscience metaphors + cognitive science,
- hardware advances + systems engineering,
- and now massive-scale data and infrastructure.
Much of that was, at some point, “not obviously useful” until it suddenly was.
Flexner’s warning: the real enemy is forced conformity
Flexner’s defense of “useless knowledge” is not only about technology; it’s about human freedom. He’s writing in a period where universities were being pushed into ideological service, and he argues that the gravest threat is not wrong ideas, but the attempt to prevent minds from ranging freely.
One of his sharpest lines: “The real enemy… is the man who tries to mold the human spirit so that it will not dare to spread its wings.”
If you read that in 2025, it lands uncomfortably close to modern pressures on research:
- “Only fund what’s immediately commercial.”
- “Only publish what’s trendy.”
- “Only study what aligns with the current institutional incentive gradient.”
- “Only build what can be shipped next quarter.”
And in AI specifically:
- “Only do work that scales.”
- “Only do benchmarks.”
- “Only do applied product wins.”
Flexner isn’t anti-application; he’s anti-premature closure.
Dijkgraaf’s update: society runs on knowledge it can’t fully see anymore
Dijkgraaf’s companion essay takes Flexner’s stance and says, essentially: look around, Flexner won. The modern world is built out of the long tail of basic research.
He gives a crisp late-20th-century example: the World Wide Web began as a collaboration tool for particle physicists at CERN (introduced in 1989, made public in 1993). He ties that to the evolution of grid and cloud computing developed to handle scientific data, technology that now undergirds everyday internet services. Then he makes a claim that matters a lot for AI policy debates: fundamental advances are public goods (i.e., they diffuse beyond any single lab or nation).That’s an especially relevant lens for AI, where:
- open ideas (architectures, optimization tricks, safety methods) propagate fast,
- but compute, data, and deployment concentrate power.
If knowledge is a public good, then a society that starves basic research is quietly selling off its future, even if it still “uses” plenty of science in the present.
AI as a case study in “useful uselessness”
Here’s a helpful way to read Flexner in the age of AI:
A) “Useless” questions that became AI infrastructure
Many of the questions that shaped AI looked abstract or niche before they became inevitable:
- How do high-dimensional models generalize?
- When does overparameterization help rather than hurt?
- What is the geometry of optimization landscapes?
- How can representation learning capture structure without labels?
- What are the limits of compression, prediction, and inference?
These don’t sound like product requirements. They sound like “useless” theory, until you realize they govern whether your model trains at all, whether it’s robust, whether it leaks private data, whether it can be aligned, and whether it fails safely.
Flexner’s point isn’t that every abstract question pays off. It’s that you can’t pre-identify the ones that will, and trying to do so narrows the search too early.
B) “Tool-making” is often the hidden payoff
Dijkgraaf emphasizes that pathbreaking research yields tools and techniques in indirect ways. (ias.edu)
AI progress has been exactly this: tool-making (optimizers, architectures, pretraining recipes, eval frameworks, interpretability methods, privacy-preserving techniques) that later becomes the platform everyone builds on.
C) The scary twist: usefulness for good and bad
Flexner also notes that discoveries can become instruments of destruction when repurposed. He uses chemical and aviation examples to make the point.
AI has the same dual-use character:
- The same generative model family can draft medical summaries or automate phishing.
- The same computer vision advances can improve accessibility or expand surveillance.
- The same inference tools can find scientific patterns or extract sensitive attributes.
Flexner’s framework doesn’t solve dual-use, but it forces honesty: the ethical challenge isn’t a reason to stop curiosity; it’s a reason to pair curiosity with governance, norms, and safeguards.
A Flexnerian reading of the current AI funding wave
We’re currently living through a paradox that Flexner would recognize instantly:
- AI is showered with investment because it’s visibly useful now.
- That investment creates pressure to define “research” as whatever improves next quarter’s metrics.
- But the next conceptual leap in AI may come from areas that look “useless” relative to today’s dominant paradigm.
If you want better long-horizon AI outcomes (i.e., robustness, interpretability, privacy, security, alignment, and scientific discovery) Flexner would argue you need institutions that protect inquiry that isn’t instantly legible as profitable.
Or in his words, you need “spiritual and intellectual freedom.”
What to do with this (three practical takeaways)
1) Keep a portfolio: fast product work + slow foundational work
Treat research like an ecosystem. If everything must justify itself immediately, you get brittle progress. Flexner’s “no promises” stance is a feature, not a bug.
2) Reward questions, not only answers
Benchmarks matter, but they can also overfit the field’s imagination. Some of the most important AI work right now is about re-framing the question (e.g., what counts as “understanding,” what counts as “alignment,” what counts as “privacy,” what counts as “truthfulness”).
3) Build institutions that protect intellectual risk
Flexner designed the Institute for Advanced Study around the idea that scholars “accomplish most when enabled” to pursue deep work with minimal distraction.
AI needs its own versions of that: spaces where the incentive is insight, not velocity.
AI is not an argument against Flexner (it’s his exhibit A)
If you hold a smartphone, use a search engine, or interact with modern AI systems, you’re touching the compounded returns of yesterday’s “useless” knowledge.
Flexner’s defense isn’t sentimental. It’s strategic: a society that wants transformative technology must also want the conditions that produce it: freedom, patience, and room for ideas that don’t yet know what they’re for. Or, as Dijkgraaf puts it in summarizing Flexner’s view: fundamental inquiry goes to the “headwaters,” and applications follow, slowly, steadily, and often surprisingly.
Main Source: https://www.ias.edu/ideas/2017/dijkgraaf-usefulness
 and the prover
and the prover 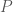 knows a valid witness
knows a valid witness  , then for all
, then for all  , the honest verifier
, the honest verifier 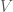 will accept the proof with probability at least
will accept the proof with probability at least  :
: ![\Pr[V(x) = \text{accept} \mid x \in L, w \text{ valid}] \geq 1 - \epsilon.](https://s0.wp.com/latex.php?latex=%5CPr%5BV%28x%29+%3D+%5Ctext%7Baccept%7D+%5Cmid+x+%5Cin+L%2C+w+%5Ctext%7B+valid%7D%5D+%5Cgeq+1+-+%5Cepsilon.&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
 , then no cheating prover
, then no cheating prover  can convince the honest verifier
can convince the honest verifier ![\Pr[V(x) = \text{accept} \mid x \not\in L] \leq \epsilon](https://s0.wp.com/latex.php?latex=%5CPr%5BV%28x%29+%3D+%5Ctext%7Baccept%7D+%5Cmid+x+%5Cnot%5Cin+L%5D+%5Cleq+%5Cepsilon&bg=ffffff&fg=4c4c4c&s=0&c=20201002) where
where  is a negligible function.,
is a negligible function., , there exists a polynomial-time simulator
, there exists a polynomial-time simulator 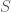 such that the output of
such that the output of  is computationally indistinguishable from the interaction between
is computationally indistinguishable from the interaction between  :
: 
 to match graph
to match graph  .
. be a proof system for a language
be a proof system for a language  . The proof system is perfect zero-knowledge if for every polynomial-time verifier
. The proof system is perfect zero-knowledge if for every polynomial-time verifier  :
: ![\Pr[\text{Transcript}(P\leftrightarrow V^*,x)=t]= \Pr[S(x)=t]\forall t,](https://s0.wp.com/latex.php?latex=%5CPr%5B%5Ctext%7BTranscript%7D%28P%5Cleftrightarrow+V%5E%2A%2Cx%29%3Dt%5D%3D+%5CPr%5BS%28x%29%3Dt%5D%5Cforall+t%2C&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
 is the transcript of the interaction between
is the transcript of the interaction between  be a proof system for a language
be a proof system for a language  and
and  are computationally indistinguishable. That is, no polynomial-time distinguisher can tell apart the real interaction and the simulated interaction with non-negligible probability.
are computationally indistinguishable. That is, no polynomial-time distinguisher can tell apart the real interaction and the simulated interaction with non-negligible probability.![\Delta(\text{Transcript}(P \leftrightarrow V^*, x), S(x)) = \frac{1}{2} \sum_t \left| \Pr[\text{Transcript} = t] - \Pr[S(x) = t] \right| \leq \epsilon,](https://s0.wp.com/latex.php?latex=%5CDelta%28%5Ctext%7BTranscript%7D%28P+%5Cleftrightarrow+V%5E%2A%2C+x%29%2C+S%28x%29%29+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Csum_t+%5Cleft%7C+%5CPr%5B%5Ctext%7BTranscript%7D+%3D+t%5D+-+%5CPr%5BS%28x%29+%3D+t%5D+%5Cright%7C+%5Cleq+%5Cepsilon%2C&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
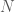 (a composite number) without revealing the factorization of
(a composite number) without revealing the factorization of  and
and  are isomorphic without revealing the isomorphism. The verifier’s view of the interaction can be statistically simulated.
are isomorphic without revealing the isomorphism. The verifier’s view of the interaction can be statistically simulated.