A recurring theme in cryptography is that correlation is a resource. Alice and Bob may start with a source correlation , say noisy copies of a bit or erasures. The hope is to convert it into a more useful target correlation . What changes dramatically is whether they are allowed to talk, and whether we only care about correctness or also about security. The recent SNIR/SNIS line of work makes that distinction precise and surprisingly rigid.
This post explains that landscape in a way I hope is useful. The main message/tl;dr is:
- ordinary non-secure non-interactive reductions ask only whether local maps can reproduce the right joint law;
- secure non-interactive reductions ask for that plus privacy against each party;
- interactive reductions are much more powerful because communication can reshape the parties’ views before the final local-output step.
Recently, I have also been working with colleagues in ECE and Physics on quantum secure non-interactive reductions, which aim to understand when one quantum correlation resource can be transformed into another quantum (or classical) resource without communication and while preserving the appropriate notion of security against each party. In the quantum setting, the picture is even more delicate: the relevant resources may be shared quantum states, measurements may disturb systems, side information may be entangled, and the right privacy conditions must account for quantum adversaries and quantum views rather than just classical random variables. Our framework for thinking about that problem relies heavily on the formalization of the classical or non-quantum version, which is the subject of this post. Put differently, before asking what secure non-interactive reducibility should mean for shared entangled states or quantum correlations, it is essential to first understand the classical theory: what ordinary non-interactive reductions allow, what secure non-interactive reductions forbid, and why interaction fundamentally changes the reducibility landscape. I will also prove a simple lemma showing that secure non-interactive reducibility is strictly stronger than ordinary non-interactive reducibility.
The three models
Fix a source correlation and a target correlation .
Non-secure non-interactive reduction (NIR / NIS)
Alice gets , Bob gets , they do no communication, and output , or randomized versions using local coins. The goal is for to be close in statistical distance (or total variation distance) to .
That is the classical non-interactive simulation perspective: only correctness of the output law matters. The SNIS paper explicitly contrasts this with SNIS, noting that NIS “only considers correctness (not security).”
Secure non-interactive reduction (SNIR / SNIS)
Now Alice and Bob still do not communicate, but in addition to correctness, the reduction must hide whatever the target correlation is supposed to hide. In the formulation used in the SNIS paper, a reduction from to must satisfy:
- Correctness: is close (in statistical distance) to .
- Security against corrupt Alice: conditioned on the final outputs , Alice’s view should be close to depending only on , not on the extra value .
- Security against corrupt Bob: symmetrically, Bob’s view should be close to depending only on , not on the extra value .
This is the key strengthening. In NIR, a party may silently carry “too much knowledge” about the other party’s output, as long as the final joint distribution looks right. In SNIR, that is disallowed.
Interactive secure reductions
Here Alice and Bob may exchange messages before producing outputs. An interactive secure reduction can be seen as having two phases. First, an interaction phase transforms the parties’ views. Second, a local derivation phase maps those final views to outputs, and the security condition applies to this derivation step.
That decomposition is conceptually important: SNIR isolates the “final local secure derivation” part while forbidding the interaction that might create the right intermediate views in the first place. This is why interactive reductions can be much stronger.
Why SNIR is the right cryptographic strengthening
NIR asks “can I simulate the right distribution?”
SNIR asks “can I simulate the right distribution without the wrong leakage?”
The SNIS paper states this very plainly: in NIS, “erasing information from parties’ views… is permissible,” but that may not be cryptographically secure. SNIS was introduced precisely to capture non-interactive secure conversion of one correlation into another. This matters because many correlations that are “equivalent enough” from a purely distributional viewpoint stop being interchangeable once one insists on simulation-based privacy.
SNIR is strictly stronger than non-secure NIR
Here is a simple lemma/example that captures the basic separation.
Lemma/example
There exist correlations and such that:
- has a perfect non-secure non-interactive reduction from , but
- has no perfect secure non-interactive reduction from .
Proof
Let be independent uniform bits.
Define the source correlation
So Alice receives the pair , while Bob receives only .
Define the target correlation
Step 1: There is a perfect non-secure non-interactive reduction
Alice outputs
and Bob outputs
No communication is used. Since are independent uniform bits, the joint distribution of is exactly , which is exactly the target correlation .
So has a perfect NIR from .
Step 2: There is no perfect secure non-interactive reduction
Assume for contradiction that the above source-to-target conversion were a perfect SNIR.
In the target correlation , Alice’s output is and Bob’s output is . Since and are independent, a correct secure realization of should not let Alice’s view reveal Bob’s output beyond what is implied by her own output .
But in the source , Alice’s view is
Conditioned on the target outputs , Alice’s view is deterministically
Hence the conditional law of Alice’s view depends on . i.e., on Bob’s output , not merely on Alice’s own output .
This violates the security-against-Alice requirement for SNIR.
Therefore no perfect SNIR from to exists.
What this lemma implies
This toy example is simple, but it isolates the exact distinction.
- In NIR, it is fine that Alice initially knows both and ; all we asked for was the right final law.
- In SNIR, that extra knowledge is fatal, because Alice learns Bob’s target output in a way the target correlation itself does not permit.
Ordinary non-interactive reduction
“Can I locally compress, discard, relabel, or threshold my view so that the joint output law matches the target?”
This is fundamentally an information-theoretic simulation question.
Secure non-interactive reduction
“Can I do that without retaining forbidden side information about the other party’s target output?”
This is a simulation-based-privacy question.
Interactive reduction
“Can I first reengineer the two views using communication, and only then derive the target securely?”
This is why interaction is stronger.
References
[1] Agarwal, Narayanan, Pathak, Prabhakaran, Prabhakaran, Rehan, “Secure Non-Interactive Reduction and Spectral Analysis of Correlations” (Eurocrypt 2022 / ePrint 2022/262), especially the spectral criterion, mirroring perspective, and incompleteness results.
[2] Bhushan, Misra, Narayanan, Prabhakaran, “Secure Non-Interactive Reducibility is Decidable” (TCC 2022 / ePrint 2022/1457), for decidability of SNIR feasibility.
[3] Khorasgani, Maji, Nguyen, “Secure Non-interactive Simulation: Feasibility and Rate” (Eurocrypt 2022), for the simulation-based definition, comparison with NIS and OWSC, and exact rate/feasibility characterizations for BSS/BES families.
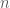 shares so that any
shares so that any 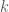 shares can reconstruct the secret, but any fewer than
shares can reconstruct the secret, but any fewer than  , a subset
, a subset  active users who must recover the final key, and possibly helpers in
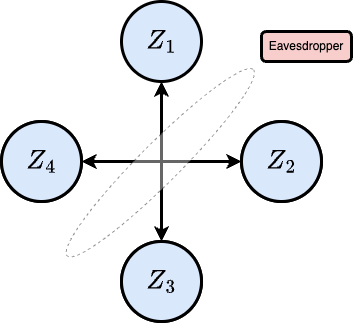
active users who must recover the final key, and possibly helpers in  . Each user has access to a private correlated source
. Each user has access to a private correlated source  , and everyone can participate in public discussion, which an eavesdropper also sees. The key must satisfy two conditions:
, and everyone can participate in public discussion, which an eavesdropper also sees. The key must satisfy two conditions: ,
, is the actual secret and the
is the actual secret and the  ‘s are random pads. Then we encode
‘s are random pads. Then we encode  using an
using an  Reed-Solomon code with generator matrix
Reed-Solomon code with generator matrix 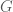 , obtaining a codeword
, obtaining a codeword  . Each terminal receives one symbol
. Each terminal receives one symbol  of this codeword, and then the protocol publicly reveals exactly
of this codeword, and then the protocol publicly reveals exactly  additional symbols. Since any
additional symbols. Since any  MDS code suffice to reconstruct the message, each legitimate terminal can combine its private symbol with the
MDS code suffice to reconstruct the message, each legitimate terminal can combine its private symbol with the  . In the “secret-sharing-inspired” version of the scheme, terminal
. In the “secret-sharing-inspired” version of the scheme, terminal  has a distinct random shared value
has a distinct random shared value  .. Each intended recipient can subtract its own mask
.. Each intended recipient can subtract its own mask  denote the data universe and let
denote the data universe and let  be the set of datasets.
be the set of datasets. are called neighbors, denoted
are called neighbors, denoted  , if they differ in the data of exactly one individual.
, if they differ in the data of exactly one individual. is said to be
is said to be -differentially private if for all neighboring datasets
-differentially private if for all neighboring datasets  ,
,![\Pr[\mathcal{M}(D)\in S] \;\le\; e^{\varepsilon}\Pr[\mathcal{M}(D')\in S] + \delta](https://s0.wp.com/latex.php?latex=%5CPr%5B%5Cmathcal%7BM%7D%28D%29%5Cin+S%5D+%5C%3B%5Cle%5C%3B+e%5E%7B%5Cvarepsilon%7D%5CPr%5B%5Cmathcal%7BM%7D%28D%27%29%5Cin+S%5D+%2B+%5Cdelta&bg=ffffff&fg=4c4c4c&s=0&c=20201002) .
. . For each
. For each  let
let  be a (possibly randomized) algorithm that, on input a dataset
be a (possibly randomized) algorithm that, on input a dataset  , outputs a random variable in some measurable output space
, outputs a random variable in some measurable output space  .
.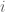 ,
,  -differentially private.
-differentially private. as follows: on input
as follows: on input  , it outputs
, it outputs 
 denotes the
denotes the  .
. denote the full transcript in the product space
denote the full transcript in the product space .
. -differentially private.
-differentially private. and
and  for all
for all  -differentially private.
-differentially private. adds across rounds. In the quantum world, however, DP is commonly defined operationally against arbitrary measurements; and this makes the usual classical composition proofs, which rely on a scalar privacy-loss random variable, no longer directly applicable.
adds across rounds. In the quantum world, however, DP is commonly defined operationally against arbitrary measurements; and this makes the usual classical composition proofs, which rely on a scalar privacy-loss random variable, no longer directly applicable.