In this blog post, we shall do a mini-survey on some results on Kemeny rank aggregation.
In social choice theory, preference or rank aggregation is the problem of combining rankings from multiple voters or users into one “central” ranking. Arrow [1] showed that no ranking or voting rule can simultaneously satisfy certain properties so we must trade off certain properties. Such a trade-off can be achieved via the Condercet winner criteria. A Condorcet winner is a candidate who beats all other candidates in head-to-head comparisons. The Condorcet winner does not always exist but if it exists, it is unique!
The Kemeny optimal ranking [2] will always yield a Condorcet winner if it exists. A Kemeny ranking is a permutation on candidates that minimizes the number of pairwise disagreements with the rankings from all voters or users. More precisely, the Kemeny ranking minimizes the Kemeny score given as follows:
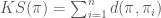
where we are given 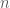
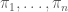
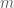


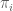
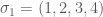


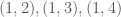


The decision version of computing the Kemeny score (i.e., for any 
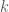
There are computationally efficient approximation algorithms to solve the problem. Here are some examples:
- KwikSort (3-approximation): KwikSort is modeled after the QuickSort algorithm for sorting items in a list. Pivotal (ah!) to the algorithm is the selection of a pivot in each recursive call. Based on the pivot, we decide to place an item before or after the pivot in rank order. See paper by Ailon, Charikar, and Newman [6] for more information.
- Borda (5-approximation): Uses Borda’s method where each item receives points based on its position in a ranking [7, 8].
- LP-Rounding (4/3-approximation): Formulates rank aggregation as an ILP (Integer Linear Program) and “relaxes” the program into an LP (Linear Program). The solution to this LP can be used to obtain a ranking with improved approximation factors (e.g., see [6]).
-
-approximation: Kenyon-Mathieu and Schudy present a PTAS (Polynomial Time Approximation Scheme) for solving rank aggregation.
Take a look at the references below for more information on background on rank aggregation and related problems (e.g., clustering).
References
[1] K.J. Arrow. Social Choice and Individual Values. Number no. 12 in Cowles Foundation
Monographs Series. Wiley, 1963.
[2] J.G. Kemeny, J.L. Snell, and Karreman Mathematics Research Collection. Mathematical
Models in the Social Sciences. Blaisdell book in the pure and applied sciences. 1962
[3] J. Bartholdi, C. A. Tovey, and M. A. Trick. Voting schemes for which it can be difficult
to tell who won the election. Social Choice and Welfare, 6(2):157–165, 1989.
[4] Cynthia Dwork, Ravi Kumar, Moni Naor, and D. Sivakumar. Rank aggregation methods
for the web. In Proceedings of the Tenth International World Wide Web Conference,
WWW 10, Hong Kong, China, May 1-5, 2001, pages 613–622, 2001.
[5] Vincent Conitzer, Andrew J. Davenport, and Jayant Kalagnanam. Improved bounds
for computing kemeny rankings. In Proceedings, The Twenty-First National Conference on Artificial Intelligence and the Eighteenth Innovative Applications of Artificial Intelligence Conference,pages 620–626, 2006.
[6] Nir Ailon, Moses Charikar, and Alantha Newman. Aggregating inconsistent information: Ranking and clustering. J. ACM, 55(5):23:1–23:27, 2008.
[7] Jean-Charles de Borda. M´emoire sur les ´elections au scrutin. Histoire de l’Acad´emie
Royale des Sciences, 1781.
[8] Don Coppersmith, Lisa Fleischer, and Atri Rudra. Ordering by weighted number of wins gives a good ranking for weighted tournaments. ACM Trans. Algorithms, 6(3):55:1–55:13, 2010.
[9] Claire Kenyon-Mathieu and Warren Schudy. How to rank with few errors. In Proceedings
of the 39th Annual ACM Symposium on Theory of Computing, San Diego, California,
USA, June 11-13, 2007, pages 95–103, 2007.
