tl;dr Recently, my research group and I have been collaborating with scientists at Amazon to design, implement, and test multi-bit watermarking schemes. We will likely release our pre-print soon. But until then, in this blog post, I present some thoughts on multi-bit text watermarking.
Text watermarking can be introduced as a digital provenance tool: a model provider slightly changes generation so that later, with the right detector, the model provider can tell (preferably with overwhelmingly high confidence) whether some generated text came from its model. That is the zero-bit version: the hidden payload or message is just “watermark present.” The more interesting version is multi-bit watermarking, where the generated text carries a message: a user ID, model ID, timestamp, content-policy tag, licensing tag, or audit trail.
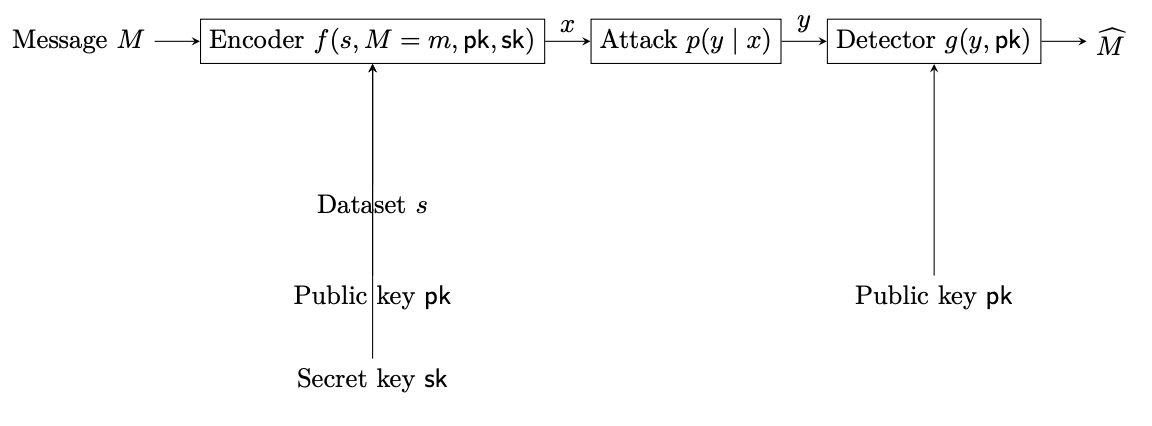
That extra payload is useful, but it creates a fundamental tension. The process of embedding more bits requires the output distribution to depend more strongly on the hidden message; stronger dependence makes decoding easier, but also makes the text easier to distinguish from ordinary model output. Our latest work (to be released soon!) states this tradeoff directly: higher payloads tend to increase detectability, while stronger distortion-free requirements reduce achievable rates.
This is not a brand new conceptual problem. It is the LLM version of a much older question in information hiding, data hiding, steganography, and digital watermarking: how many bits can be hidden in a host object while preserving some notion of distributional fidelity, stealth, or robustness? Moulin and O’Sullivan’s information-theoretic analysis describes information hiding as hiding information in a host data set so that it can be reliably communicated to a receiver, covering watermarking, fingerprinting, steganography, and data embedding [1]. Cachin’s information-theoretic steganography model casts the adversary’s task as a hypothesis test between innocent cover messages and stego messages, with security quantified through distributional divergence [2]. Chen and Wornell’s quantization-index modulation work studies embedding a signal, such as a digital watermark, inside a host signal to form a composite signal, with provable rate-distortion-robustness behavior [3].
The LLM twist is that the “host” is not a fixed image, audio clip, or document. It is a next-token distribution. At each generation step, the base model gives a distribution (

From zero-bit detection to multi-bit communication
A zero-bit watermark asks:


A multi-bit watermark asks a stronger question about the following relation:

where 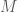


Early LLM watermarking work focused largely on zero-bit detection. Kirchenbauer et al.’s watermark, for example, randomly selects “green” tokens before generation and softly promotes them during sampling, giving an efficient statistical detector [4]. SynthID-Text is another prominent watermarking system for LLM outputs, described as preserving text quality while enabling efficient detection with minimal latency overhead. [5] Multi-bit schemes move beyond detection into payload extraction; for example, multi-bit text watermarking methods have been proposed for traceability, robust extraction, and paraphrase-resilient embedding.
Our work frames this shift using an information-theoretic channel view: reliable message recovery is governed by the conditional mutual information of the induced watermark channel, and different distortion regimes create different capacity-detectability frontiers.
The basic channel model
Let 
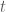

a next-token distribution conditioned on the previous context. A multi-bit watermark has:

as the message, and a secret key or side information 


then samples

The key design constraint is that each conditional law 


This definition matters because total variation has an operational meaning: it is exactly the largest possible distinguishing advantage of any detector trying to decide whether a sample came from 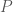

Total variation is maximum distinguishing advantage
Let 
![\Pr_{X\sim P}[\phi(X)=1] - \Pr_{X\sim Q}[\phi(X)=1]](https://s0.wp.com/latex.php?latex=%5CPr_%7BX%5Csim+P%7D%5B%5Cphi%28X%29%3D1%5D+-+%5CPr_%7BX%5Csim+Q%7D%5B%5Cphi%28X%29%3D1%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
For a fixed detector,
![\mathbb E_P[\phi(X)]-\mathbb E_Q[\phi(X)] = \sum_x \phi(x)(P(x)-Q(x)).](https://s0.wp.com/latex.php?latex=%5Cmathbb+E_P%5B%5Cphi%28X%29%5D-%5Cmathbb+E_Q%5B%5Cphi%28X%29%5D+%3D+%5Csum_x+%5Cphi%28x%29%28P%28x%29-Q%28x%29%29.&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
Let

Since 

But

The upper bound is achieved by the detector 
![\sup_\phi \left| \Pr_{P}[\phi(X)=1]-\Pr_Q[\phi(X)=1]\right| = d_{\mathrm{TV}}(P,Q).](https://s0.wp.com/latex.php?latex=%5Csup_%5Cphi+%5Cleft%7C+%5CPr_%7BP%7D%5B%5Cphi%28X%29%3D1%5D-%5CPr_Q%5B%5Cphi%28X%29%3D1%5D%5Cright%7C+%3D+d_%7B%5Cmathrm%7BTV%7D%7D%28P%2CQ%29.&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
So a per-token TV budget is a bound on the best possible one-token test. In our work, we have been using the TV budget to implement watermarking schemes and test the detectability and message-recoverability of such schemes.
How this relates to information hiding, data hiding, and steganography
The terminology across communities is inconsistent, but the underlying mathematical formulation is (fairly) stable.
Information hiding is the broad umbrella. There is a host object, a hidden message, a distortion or detectability constraint, and a receiver. The goal is reliable communication through the host.
Data hiding often emphasizes embedding payload bits into media. The fidelity constraint may be perceptual: image distortion, audio quality, semantic preservation, or edit distance.
Digital watermarking often emphasizes provenance, ownership, authentication, or tracing. The hidden message may be a copyright mark, model identifier, user identifier, or policy tag. Robustness against attacks is often central.
Steganography emphasizes secrecy of the very existence of communication. The adversary’s detection problem is primary. Cachin’s model, with a passive adversary distinguishing cover from stego distributions, is especially close to modern distributional formulations of LLM watermark stealth.
Multi-bit LLM watermarking sits at the intersection. It is data hiding because it embeds a payload. It is watermarking because the payload is usually provenance or attribution metadata. It is steganography when the watermarked output must be statistically indistinguishable from ordinary model output. It is channel coding because reliable recovery is governed by mutual information and error-correcting codes.
Our work explicitly connects LLM watermarking to the information-theoretic literature on watermarking, data hiding, and steganography, noting that classical work models watermarking as communication over a constrained channel and that the LLM setting replaces perceptual host distortion with distributional constraints on the base next-token law.
The central frontier
In my opinion, a good multi-bit watermark should satisfy at least three of these:
- Payload: many bits per token.
- Reliability: low message error after generation and possible edits.
- Distortion-freeness/Stealth/Low-detectability: small statistical distance from ordinary model output.
- Utility: low degradation of fluency, factuality, reasoning, and user experience.
Core results in information theory imply that these cannot all be maximized simultaneously. Stronger distortion-free constraints reduce mutual information. More robustness requires redundancy. More redundancy lowers rate. More aggressive perturbations improve decoding but increase detectability and may degrade quality.
The right question is not “Can we make a perfect multi-bit watermark?” It is: What is the best achievable rate at a given detectability, robustness, and quality budget?
That is a capacity question!
References
[1] Pierre Moulin and Joseph A. O’Sullivan. Information-theoretic analysis of information hiding. IEEE Trans. Inf. Theory, 49(3):563–593, 2003.
[2] Christian Cachin. An information-theoretic model for steganography. Information and Computation, 192(1):41–56, 2004.
[3] B. Chen and G. W. Wornell. Quantization index modulation: a class of provably good methods for digital watermarking and information embedding. IEEE Trans. Inf. Theory, 47(4):1423–1443, September 2006.
[4] John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. In Proceedings of the 40th International Conference on Machine Learning, 2023.
[5] Sumanth Dathathri, Abigail See, Sumedh Ghaisas, Po-Sen Huang, Rob McAdam, Johannes Welbl, Vandana Bachani, Alex Kaskasoli, Robert Stanforth, Tatiana Matejovicova, Jamie Hayes, Nidhi Vyas, Majd Merey, Jonah Brown-Cohen, Rudy Bunel, Borja Balle, Ali Cemgil, Zahra Ahmed, Kitty Stacpoole, and Pushmeet Kohli. Scalable watermarking for identifying large language model outputs. Nature, 634:818–823, 2024.
