
The cardinality of a collection A (which might be an ordered or unordered list, a set, or what not) is basically the number of unique values in A. For example, the collections [1,2,3,4] and [1,2,1,3,1,4,3] have the same cardinality of 4 (and also correspond to the same set).
Determing the Cardinality of a Collection: The Naive Approach
Consider a collection A=[1,2,1,3,1,4,3]. How can we systematically determine the cardinality of A? Well, here are two of many ways to do this:
- First sort A in ascending order. Then, we can perform a linear scan on A to remove duplicates. It’s pretty easy to see how this can be done. Finally, return the size of the possibly trickled-down collection (now a set) obtained. If the initial size of A is
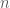 . Then, the cardinality of A, using this method, can be determined in
. Then, the cardinality of A, using this method, can be determined in  (if we use merge-sort) time and
(if we use merge-sort) time and 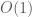 extra space.
extra space.
- Use a hash table: Perform a linear scan of A, hashing the values of A. It’s easy to see that cardinality of A is the number of keys in the hash table obtained. This uses
 time but extra space also.
time but extra space also.
Notice that we can’t do any better (lower upper-bound) than because we have to look at the entire input (which is of size ). But can we determine the cardinality of A in time using sub-linear space (using strictly smaller space than )?
That’s where probability comes in.
Linear Probabilistic Counting
This is a probabilistic algorithm for counting the number of unique values in a collection. It produces an estimation with an arbitrary accuracy that can be pre-specified by the user using only a small amount of space that can also be pre-specified. The accuracy of linear counting depends on the load factor (think hash tables) which is the number of unique values in the collection divided by the size of the collection. The larger the load factor, the less accurate the result of the linear probabilistic counter. Correspondingly, the smaller the load factor, the more accurate the result. Nevertheless, load factors much higher than 1 (e.g. 16) can be used while achieving high accuracy in cardinality estimation (e.g. <1% error).
Note: in simple hashing, the load factor cannot exceed 1 but in linear counting, the load factor can exceed 1.
Linear counting is a two-step process. In step 1, the algorithm allocates a bit map of a specific size in main memory. Let this size be some integer 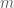 . All entries in the bit map are initialized to “0”‘s. The algorithm then scans the collection and applies a hash function to each data value in the collection. The hash function generates a bit map address and the algorithm sets this addressed bit to “1”. In step 2, the algorithm first counts the number of empty bit map entries (equivalently, the number of entries set to “0”). It then estimates the cardinality of the collection by dividing this count by the bit map size (thus obtaining the fraction of empty bit map entries. Call this
. All entries in the bit map are initialized to “0”‘s. The algorithm then scans the collection and applies a hash function to each data value in the collection. The hash function generates a bit map address and the algorithm sets this addressed bit to “1”. In step 2, the algorithm first counts the number of empty bit map entries (equivalently, the number of entries set to “0”). It then estimates the cardinality of the collection by dividing this count by the bit map size (thus obtaining the fraction of empty bit map entries. Call this 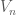 ).
).
Plug in and into the equation  to obtain
to obtain  which is the estimated cardinality of the collection. The derivation of this equation is detailed in this paper[1].
which is the estimated cardinality of the collection. The derivation of this equation is detailed in this paper[1].
Here’s my simple implementation of the Linear Probabilistic Counting Algorithm.
Errors in Counting
Although the linear probabilistic counting method is faster than deterministic approaches, it might sometimes fail to be accurate as explained above. So this method should be used only when 100% accuracy is not needed. For example, in determining the number of unique visitors to a website.
Probabilistic Alternatives to Linear Probabilistic Counting
The HyperLogLog algorithm is such an alternative. It also runs in linear time (linear in the size of the initial collection). But the HyperLogLog counter usually gives a more accurate estimation of the cardinality count and also uses less space. See this paper for more details on the HyperLogLog counter.
References
[1] A Linear-time Probablistic Counting Algorithm for Database Applications
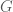 be a graph with vertex degree denoted by
be a graph with vertex degree denoted by  for vertex
for vertex  . Consider the following matrix
. Consider the following matrix  :
:
 is then defined by
is then defined by 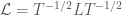 , where
, where 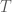 is the diagonal matrix with
is the diagonal matrix with  -th entry having value
-th entry having value 
 on
on  ), and 2.
), and 2. on
on  and
and 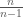 with multiplicity
with multiplicity  .
. on
on 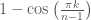 for
for 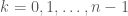 .
. with equality holding if and only if
with equality holding if and only if  . If
. If 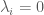 and
and  , then
, then  connected components.
connected components.