Introduction
Recently, my collaborators and I released a paper [2] (also see concurrent work of [6]) about privately
estimating a Gaussian using polynomial-time algorithms. We give the first computationally-efficient
algorithms for estimating a Gaussian (in total variation distance) subject to pure or approximate
differential privacy (DP) guarantees. In the pure DP setting, via a new lower bound, we show that
a dependence on the condition number is necessary. However, in the approximate DP setting, our
sample complexity bound does not depend on the condition number and the algorithms rely on a
method of stabilizing convex relations. Our work leverages the powerful sum-of-squares framework,
which I will try to discuss briefly—from my own vantage point—in this blog post. For a more
pedagogical and complete introduction, please see textbooks or review articles (e.g., [1, 10, 4, 5]).
Semidefinite Programming
Semidefinite Programming (SDP) involves minimizing a linear function of a variable 

where 





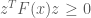

over symmetric 
![\min Tr(CX) \text{ s.t. } Tr(A_i X) = b_i\,\forall i\in[m], X\succeq 0,](https://s0.wp.com/latex.php?latex=%5Cmin+Tr%28CX%29+%5Ctext%7B+s.t.+%7D+Tr%28A_i+X%29+%3D+b_i%5C%2C%5Cforall+i%5Cin%5Bm%5D%2C+X%5Csucceq+0%2C+&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
where 

Note that 
An SDP is a convex optimization problem since the objective and constraints are convex. Also SDP includes linear programming (LP) as a special case. Thus, semidefinite programming is a generalization of linear programming where componentwise inequalities between vectors are replaced by matrix inequalities. Many LP solvers can handle semidefinite programs with some important caveats: duality results are weaker for semidefinite programs and some nonlinear, but convex, optimization problems can be cast as SDPs but not an LP. For example, consider the problem

Then using Schur complements (an exercise for the reader, perhaps) and the introduction of a new auxilliary variable 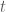
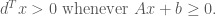



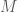
The main reason to study and utilize semidefinite programming is because the programs can be solved efficiently both in theory and practice. For example, see this Github page that contains instructions on how to run some SoS solvers: https://github.com/sums-of-squares/sos [1].
Sum-of-Squares (SoS) Hierarchy
The SoS hierarchy is a family of convex relaxations to polynomial optimization problems (dating back to the early 2000s). The hierarchy was independently formulated by Parrilo, Lasserre, and Shor for the study of polynomial optimization [11, 8, 9, 12]. While its study began as a tool in the optimization and control literature, SoS has found profound use in proof systems. It has also sparked interest in possibly refuting conjectures related to hardness of approximation and average-case complexity [3]. In the area of average-case complexity, the goal is to design algorithms that perform well on typical instances, rather than every instance. For example, Max-Clique is NP-hard to approximate but a greedy algorithm can find a clique of size 
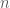
The degree-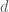

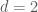
Polynomial Optimization
Let 
![{g_i}_{i\in[m]}](https://s0.wp.com/latex.php?latex=%7Bg_i%7D_%7Bi%5Cin%5Bm%5D%7D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)


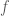
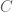
body. For SoS, the separation oracle is well-defined in terms of pseudo-distributions. Essentially, a degree-
SoS “certificate” for non-negativity of a function 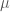
Let 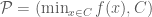
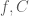



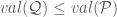

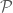
Sum-of-Squares (SoS) Relaxations and Duality
Essentially, a degree-
Remark: This is a technical condition that induces the right formulation. e.g., can mimic treating squares of degree-
MaxCut, SoS versus Other SDP Hierarchies
Karp famously showed that MaxCut is NP-hard. Let 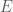
![\max_{x\in\mathbb{R}^n}\sum_{(i, j)\in E}\frac{1}{2}(1-x_ix_j),\text{ s.t. } x_i^2 = 1\, \forall i\in[n].](https://s0.wp.com/latex.php?latex=%5Cmax_%7Bx%5Cin%5Cmathbb%7BR%7D%5En%7D%5Csum_%7B%28i%2C+j%29%5Cin+E%7D%5Cfrac%7B1%7D%7B2%7D%281-x_ix_j%29%2C%5Ctext%7B+s.t.+%7D+x_i%5E2+%3D+1%5C%2C+%5Cforall+i%5Cin%5Bn%5D.&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
Consider the following degree-2 SoS relaxation of MaxCut
which turns out to be equivalent to the Goemans-Williamson relaxation. Higher degree relaxations give better approximations but with a corresponding increase in runtime.
![\max_{X\in\mathbb{R}^{n\times n}}\sum_{(i, j)\in E}\frac{1}{2}(1-X_{i j}),\text{ s.t. } X_{i i} = 1\,\forall i\in[n], X_\emptyset = 1, X\succeq 0.](https://s0.wp.com/latex.php?latex=%5Cmax_%7BX%5Cin%5Cmathbb%7BR%7D%5E%7Bn%5Ctimes+n%7D%7D%5Csum_%7B%28i%2C+j%29%5Cin+E%7D%5Cfrac%7B1%7D%7B2%7D%281-X_%7Bi+j%7D%29%2C%5Ctext%7B+s.t.+%7D+X_%7Bi+i%7D+%3D+1%5C%2C%5Cforall+i%5Cin%5Bn%5D%2C+X_%5Cemptyset+%3D+1%2C+X%5Csucceq+0.&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
Thus far, we have only considered the primal view of SoS relaxations. The dual view is quite powerful: it gives us ways to certify that a SoS relaxation has a value 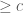

There are other semidefinite programming hierarchies, such as Sherali-Adams and the Approximate Lassserre hierarchies [7, 5]. In my opinion, the main difference between SoS and other hierarchies is that SoS treats all polynomials equally and others (e.g., Lasserre) do not and so are not agnostic to the basis choice.
Acknowledgements
Thanks to Daniel Hsu for comments on a preliminary draft.
References
[1] G. Valmorbida S. Prajna P. Seiler P. A. Parrilo M. M. Peet A. Papachristodoulou, J. Anderson
and D. Jagt. SOSTOOLS: Sum of squares optimization toolbox for MATLAB. 2021. Available
from https://github.com/oxfordcontrol/SOSTOOLS.
[2] Daniel Alabi, Pravesh K. Kothari, Pranay Tankala, Prayaag Venkat, and Fred Zhang. Privately
estimating a gaussian: Efficient, robust and optimal. CoRR, abs/2212.08018, 2022.
[3] Boaz Barak, Fernando G.S.L. Brandao, Aram W. Harrow, Jonathan Kelner, David Steurer,
and Yuan Zhou. Hypercontractivity, sum-of-squares proofs, and their applications. In Proceedings of the Forty-Fourth Annual ACM Symposium on Theory of Computing, STOC ’12, page 307–326, 2012.
[4] Grigoriy Blekherman, Pablo A. Parrilo, Rekha R. Thomas, Grigoriy Blekherman, Pablo A.
Parrilo, and Rekha R. Thomas. Semidefinite Optimization and Convex Algebraic Geometry.
Society for Industrial and Applied Mathematics, 2012.
[5] Noah Fleming, Pravesh Kothari, and Toniann Pitassi. Semialgebraic proofs and efficient algorithm design. Foundations and Trends® in Theoretical Computer Science, 14(1-2):1–221, 2019.
[6] Samuel B. Hopkins, Gautam Kamath, Mahbod Majid, and Shyam Narayanan. Robustness implies privacy in statistical estimation. CoRR, abs/2212.05015, 2022.
[7] Jean B. Lasserre. Global optimization with polynomials and the problem of moments. SIAM J. Optim., 11(3):796–817, 2001.
[8] Jean B. Lasserre. New Positive Semidefinite Relaxations for Nonconvex Quadratic Programs, pages 319–331. Springer US, Boston, MA, 2001.
[9] Jean B. Lasserre. Semidefinite programming vs. lp relaxations for polynomial programming. Mathematics of Operations Research, 27(2):347–360, 2002.
[10] M. Laurent. Sums of squares, moment matrices and optimization over polynomials, pages 155–270. Number 149 in The IMA Volumes in Mathematics and its Applications Series. Springer Verlag, Germany, 2009.
[11] Pablo A. Parrilo. Structured semidefinite programs and semialgebraic geometry methods in robustness and optimization. Dissertation (Ph.D.), California Institute of Technology, 2000.
[12] Naum Z Shor. Quadratic optimization problems. Soviet Journal of Computer and Systems Sciences, 25(1):1–11, 1987.
